띄어쓰기 태깅
먼저 띄어쓰기에 대한 태깅 합니다.
NER과 동일한 방법으로 각 토큰을 BI로 표현해보겠습니다.
word 기준이 아닌 char 기준으로 태깅을 합니다.
1
2
3
4
5
6
7
8
|
sentence = "그 외 기간은 관계자 외 출입금지입니다.".split(" ")
tags = []
for word in sentence:
for i in range(len(word)):
if i == 0:
tags.append("B")
else:
tags.append("I")
|
1
2
|
>> tags
['B', 'B', 'B', 'I', 'I', 'B', 'I', 'I', 'B', 'B', 'I', 'I', 'I', 'I', 'I', 'I', 'I']
|
Custom Dataset 생성
위 내용을 이용해 pytorch custom dataset을 만들어 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
from typing import Callable, List, Tuple
from torch.utils.data import Dataset
class CorpusDataset(Dataset):
def __init__(self, data_path: str):
self.sentences = []
self.slot_labels = ["UNK", "PAD", "B", "I"]
self._load_data(data_path)
def _load_data(self, data_path: str):
"""data를 file에서 불러온다.
Args:
data_path: file 경로
"""
with open(data_path, mode="r", encoding="utf-8") as f:
lines = f.readlines()
self.sentences = [line.split() for line in lines]
def _get_tags(self, sentence: List[str]) -> List[str]:
"""문장에 대해 띄어쓰기 tagging을 한다.
character 단위로 분리하여 BI tagging을 한다.
Args:
sentence: 문장
Retrns:
문장의 각 토큰에 대해 tagging한 결과 리턴
["B", "I"]
"""
tags = []
for word in sentence:
for i in range(len(word)):
if i == 0:
tags.append("B")
else:
tags.append("I")
return tags
def __len__(self):
return len(self.sentences)
def __getitem__(self, idx):
pass
|
띄어쓰기에 대한 표현은 완성이 되었고, 이제 한글 문장을 BERT의 input feature로 만들어 보겠습니다.
input feature를 만드는 transform function을 넘겨받아 __getitem__()에 해당 내용을 추가합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
from typing import Callable, List, Tuple
from torch.utils.data import Dataset
class CorpusDataset(Dataset):
def __init__(self, data_path: str, transform: Callable[[List, List], Tuple]):
self.sentences = []
self.slot_labels = ["UNK", "PAD", "B", "I"]
self.transform = transform
self._load_data(data_path)
def _load_data(self, data_path: str):
"""data를 file에서 불러온다.
Args:
data_path: file 경로
"""
with open(data_path, mode="r", encoding="utf-8") as f:
lines = f.readlines()
self.sentences = [line.split() for line in lines]
def _get_tags(self, sentence: List[str]) -> List[str]:
"""문장에 대해 띄어쓰기 tagging을 한다.
character 단위로 분리하여 BI tagging을 한다.
Args:
sentence: 문장
Retrns:
문장의 각 토큰에 대해 tagging한 결과 리턴
["B", "I"]
"""
tags = []
for word in sentence:
for i in range(len(word)):
if i == 0:
tags.append("B")
else:
tags.append("I")
return tags
def __len__(self):
return len(self.sentences)
def __getitem__(self, idx):
sentence = "".join(self.sentences[idx])
sentence = [s for s in sentence]
tags = self._get_tags(self.sentences[idx])
tags = [self.slot_labels.index(t) for t in tags]
(
input_ids,
attention_mask,
token_type_ids,
slot_label_ids,
) = self.transform(sentence, tags)
return input_ids, attention_mask, token_type_ids, slot_label_ids
|
그럼 transform function을 구현해보겠습니다.
pretrained model는 KoBERT를 사용합니다.
BERT의 input은 다음와 같습니다.
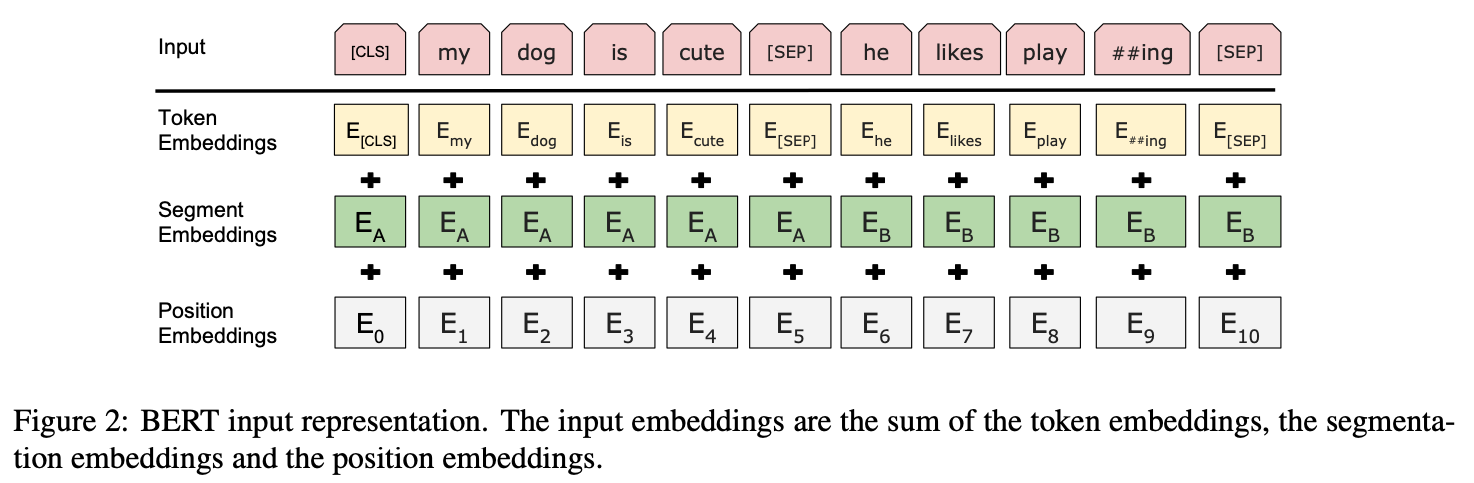
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
import torch
from typing import List, Tuple
from tokenization_kobert import KoBertTokenizer
class Preprocessor:
def __init__(self, max_len: int):
self.tokenizer = KoBertTokenizer.from_pretrained("monologg/kobert")
self.max_len = max_len
self.pad_token_id = 0
def get_input_features(
self, sentence: List[str], tags: List[str]
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
"""문장과 띄어쓰기 tagging에 대해 feature로 변환한다.
Args:
sentence: 문장
tags: 띄어쓰기 tagging
Returns:
feature를 리턴한다.
input_ids, attention_mask, token_type_ids, slot_labels
"""
input_tokens = []
slot_label_ids = []
# tokenize
for word, tag in zip(sentence, tags):
tokens = self.tokenizer.tokenize(word)
if len(tokens) == 0:
tokens = self.tokenizer.unk_token
input_tokens.extend(tokens)
for i in range(len(tokens)):
if i == 0:
slot_label_ids.extend([tag])
else:
slot_label_ids.extend([self.pad_token_id])
# max_len보다 길이가 길면 뒤에 자르기
if len(input_tokens) > self.max_len - 2:
input_tokens = input_tokens[: self.max_len - 2]
slot_label_ids = slot_label_ids[: self.max_len - 2]
# cls, sep 추가
input_tokens = (
[self.tokenizer.cls_token] + input_tokens + [self.tokenizer.sep_token]
)
slot_label_ids = [self.pad_token_id] + slot_label_ids + [self.pad_token_id]
# token을 id로 변환
input_ids = self.tokenizer.convert_tokens_to_ids(input_tokens)
attention_mask = [1] * len(input_ids)
token_type_ids = [0] * len(input_ids)
# padding
pad_len = self.max_len - len(input_tokens)
input_ids = input_ids + ([self.tokenizer.pad_token_id] * pad_len)
slot_label_ids = slot_label_ids + ([self.pad_token_id] * pad_len)
attention_mask = attention_mask + ([0] * pad_len)
token_type_ids = token_type_ids + ([0] * pad_len)
input_ids = torch.tensor(input_ids, dtype=torch.long)
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
token_type_ids = torch.tensor(token_type_ids, dtype=torch.long)
slot_label_ids = torch.tensor(slot_label_ids, dtype=torch.long)
return input_ids, attention_mask, token_type_ids, slot_label_ids
|
dataset을 생성할때 transform으로 get_input_features() 넣어주면, dataset에서 데이터를 불러올 때마다 수행이 되어 input feature로 만들어지게 됩니다.
1
2
|
preprocessor = Preprocessor(config.max_len)
dataset = CorpusDataset(data_path, preprocessor.get_input_features)
|
이상으로 데이터셋 전처리가 완성되었습니다.
Reference