[논문리뷰] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Contents
ABSTRACT
pretraining 단계에서 모델 사이즈를 크게 하는 것은 downstream task에서 성능 향상을 가져왔지만, 더 많은 GPU 자원이 필요하고 학습시간도 더 오래 걸리게 되었다.
이 문제를 해결하기 위해 2가지의 parameter reduction 방법과 sentence 간의 관계의 일관성을 모델링하는 self-supervised loss를 사용하였다.
INTRODUCTION
거대한 네트워크를 구성하는 것이 state of the art performance를 기록하는데 중요한 요인이 되었으며, 큰 모델을 pretrain하고 작은 모델로 distill 하는 것이 관행처럼 되었다.
현재의 sota 모델은 수백만 혹은 수십억개의 parameters를 가지고 있어 memory limitations 문제가 존재하며, distributed training을 하는데 communication overhead가 발생하여 training speed에 영향을 주게 된다.
A Lite BERT(ALBERT)는 memory limitation과 communication overhead를 해결하기 위해 BERT에 비해 parameters를 대폭 줄인 모델이다.
ALBERT는 2가지 parameter reduction 방법을 사용한다.
첫째는 factorized embedding parameterization이다. 커다란 vocubulary embedding matrix를 2개의 small matrices로 decomposing하는 방법이다. 이렇게 함으로써, vocubulary embedding의 parameter size 증가 없이, hidden size를 쉽게 증가시킬 수 있다.
둘째는 cross-layer parameter sharing이다. 이는 network의 깊이에 따라 parameter가 증가하는 것을 방지한다.
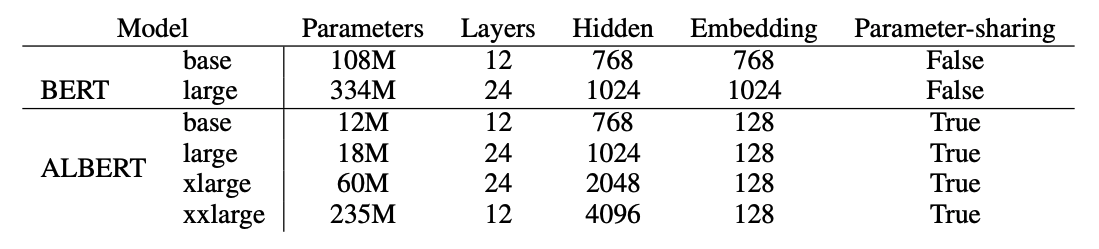
ALBERT의 설정은 BERT-large와 비슷한데, 이 2가지 설정을 통해 parameters는 18배 적어지고, 학습 속도는 1.7배 빠르게 학습할 수 있게 되었다.
이 parameter reduction 방법은 regularization과 generalization의 역할도 수행한다.
또한 ALBERT의 성능을 향상시키기 위해 sentence-order prediction(SOP)를 사용하였다. SOP는 문장 간의 관계에 대한 일관성과, BERT의 NSP의 비효율성을 개선하기 위해 사용되었다.
THE ELEMENTS OF ALBERT
Factorized embedding parameterization
BERT에서는 WordPiece embedding size E와 hidden size H를 동일하게 사용하는데, 이는 최선의 방법이 아니다.
modeling 관점에서 WordPiece embedding은 context-independent representations를 학습하는 것을 의미하고, hidden-layer embeddings은 context-dependent representations를 학습하는 것을 의미한다.
그렇기 때문에 WordPiece embedding size E와 hidden size H를 다르게, 특히 H를 E보다 크게하면 model parameter를 더욱 효율적으로 사용할 수 있다.
practical 관점에서 보통 vocabulary는 커다란 size인 V를 사용하는데, H를 크게 하면 embedding matrix도 V x E로 매우 커지게 된다.
그래서 ALBERT에서는 embedding parameters를 2개의 작은 matrix로 decomposing한다. E size의 embedding layer에 바로 projection하지 않고, 작은 크기의 E에 projection 후 hidden layer에 projection한다. 그래서 파라미터 개수는 O(V x H)에서 O(V x E + E x H)로 줄어들게 된다. 이 방법은 H가 E보다 클 때 중요하다.
Cross-layer parameter sharing
ALBERT에서는 전체 layer의 parameters를 공유한다.
Inter-sentence coherence loss
NSP는 downstream task의 성능을 높이기 위해 사용되었으나, 최근의 연구에서는 NSP의 효과에 대해 부정적인 의견을 많이 보여왔다.
NSP가 비효율적인 이유는 MLM에 비해 쉬운 task이기 때문이다. NSP에는 segment의 topic이 같은지 prediction하는 문제(topic prediction)와 segment가 일관되었는지 prediction하는 문제(coherence prediction)가 혼제되어 있다. topic prediction은 coherence prediction에 비해 쉽고, MLM과 겹치는 부분이 존재한다.
그래서 ALBERT에서는 inter-sentence coherence를 집중적으로 학습하는 sentence-order prediction(SOP)를 제안한다. positive example은 동일한 문서에서 연속적인 segments를 추출하고, negative example로는 동일한 문서에서 연속적인 segments를 추출하지만 순서를 바꾸어, segments의 순서가 맞는지 확인하는 task를 진행한다.
학습 결과 SOP는 NSP task를 풀 수 있지만, NSP는 SOP task를 풀 수 없었고, SOP가 downstream task에서 성능 향상을 이루었다.
MODEL SETUP
EXPERIMENTAL RESULTS
EXPERIMENTAL SETUP
BERT와의 비교를 위해 동일한 데이터셋을 사용하였고, input format도 “[CLS] x1 [SEP] s2 [SEP]“로 하였다.
input length는 512로 제한하였고, 10%의 확률로 512보다 짧은 sequence도 생성하였다.
vocabulary 크기는 30,000이며, XLNet에서 사용한 SentencePiece를 사용해 tokenize하였다. SpanBERT에서 사용한 n-gram masking을 이용하여 masked input을 생성하였다.
batch size는 4,096을 사용하였으며, 0.00176 learning rate의 LAMB optimizer를 사용하였다. 모든 모델은 125,000 steps를 학습하였다.
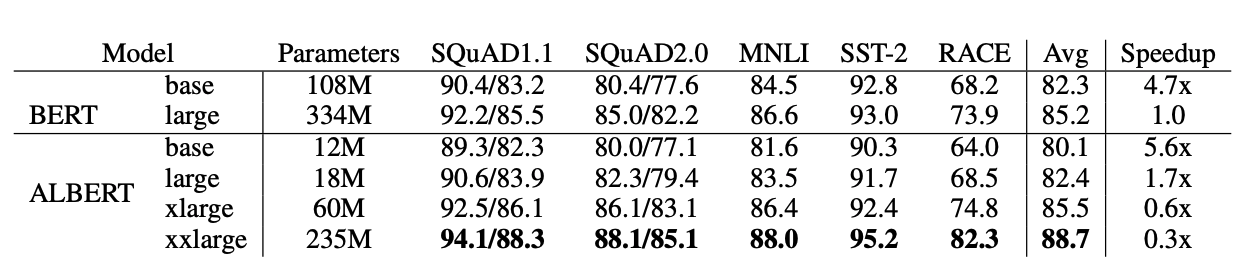
OVERALL COMPARISON BETWEEN BERT AND ALBERT EVALUATION
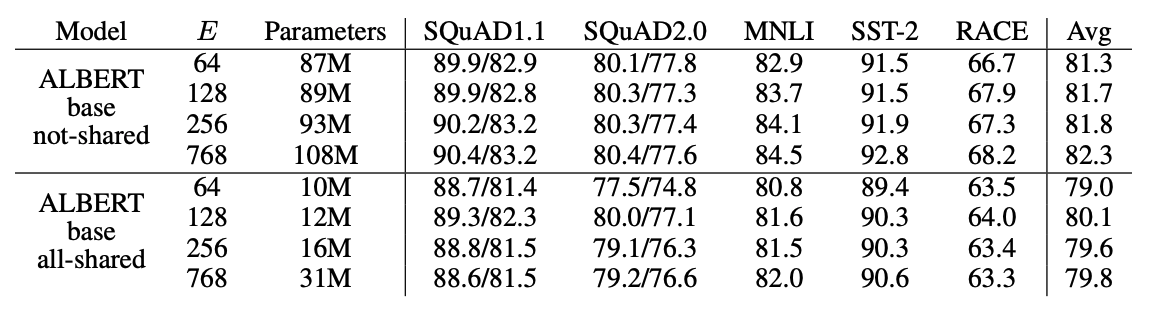
FACTORIZED EMBEDDING PARAMETERIZATION
CROSS-LAYER PARAMETER SHARING
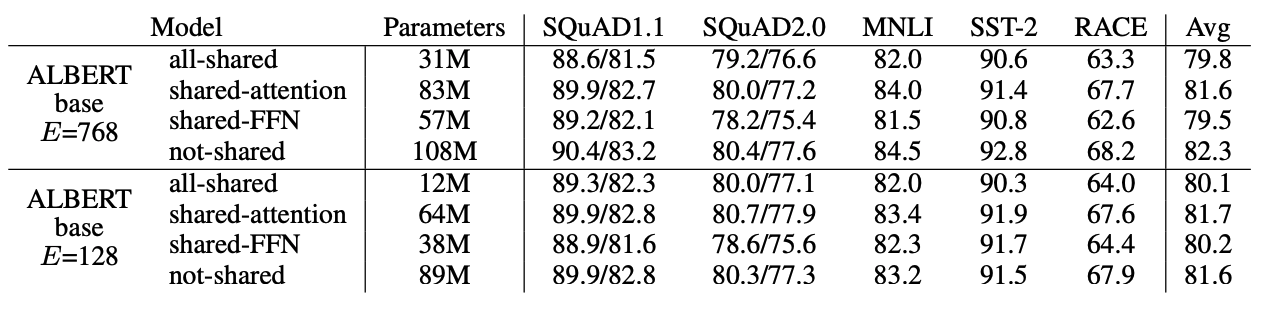
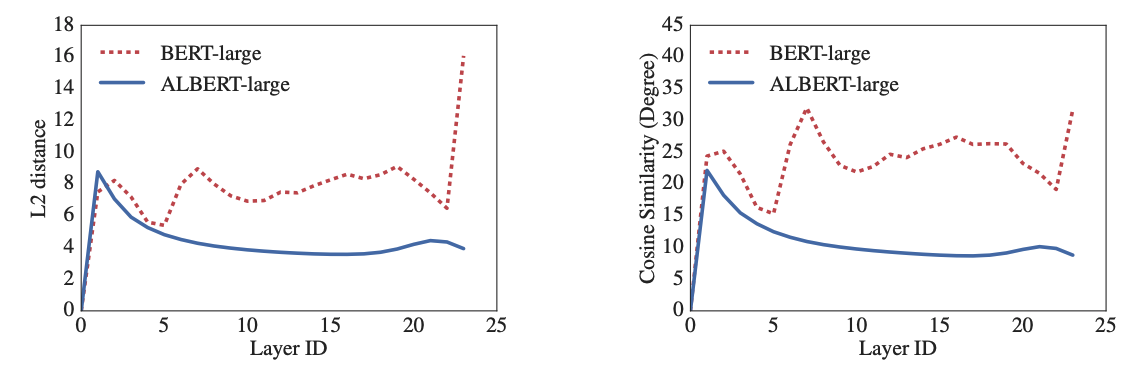
FFN을 share할때 성능 하락이 발생하며, attention을 share할때는 not-shared와 비슷한 성능을 보인다.
추가적으로 L layers를 M size의 N개의 group으로 나누어 parameter share를 하는 실험을 진행하였다. M을 작게할수록 성능 향상을 보였지만, 반대로 parameters는 기하급수적으로 증가하는 성향을 보였다.
결론적으로 ALBERT에서는 all-shared를 사용하였다.
SENTENCE ORDER PREDICTION (SOP)

NSP로 학습한 것은 SOP에서 나쁜 성능을 보였고, SOP로 학습한 모델은 NSP에서 상대적으로 좋은 성능을 보였다. 또한 SOP로 학습한 모델이 여러 downstream tasks에서 성능 향상을 보였다.
WHAT IF WE TRAIN FOR THE SAME AMOUNT OF TIME?

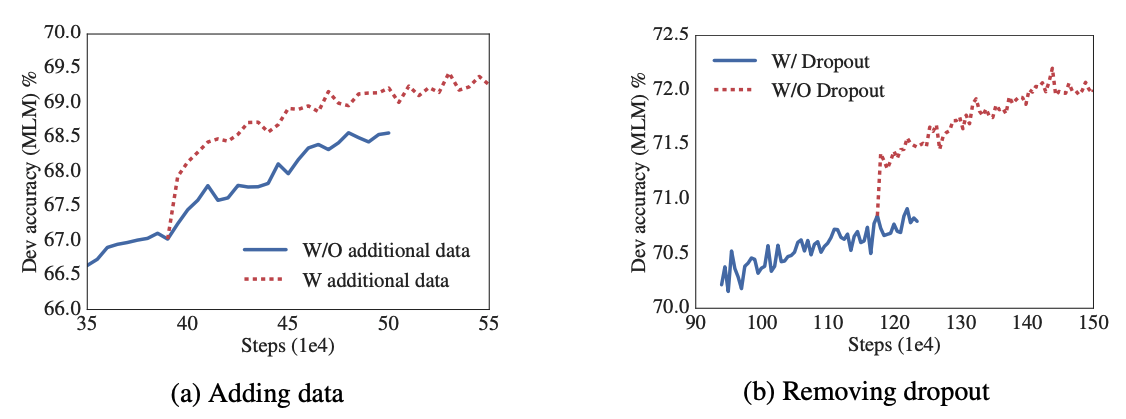
ADDITIONAL TRAINING DATA AND DROPOUT EFFECTS


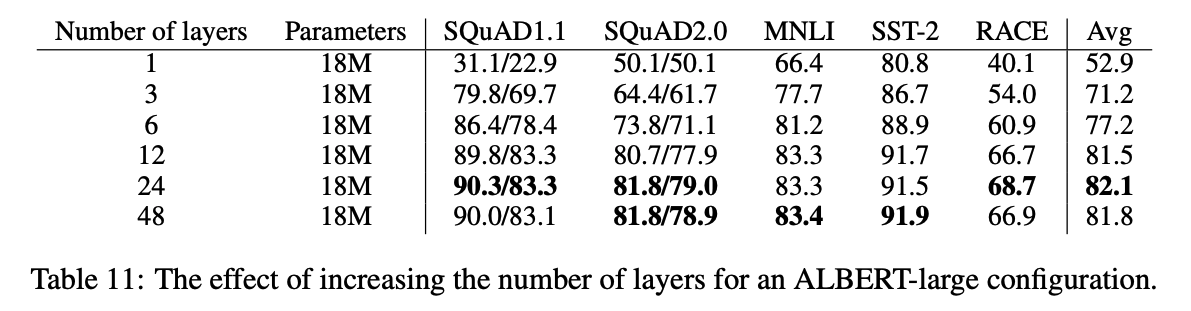
EFFECT OF NETWORK DEPTH AND WIDTH