[논문리뷰] Bert: Pre-training of deep bidirectional transformers for language understanding
Contents
Abstract
BERT(Bidirectional Encoder Representations from Transformers)는 모든 layer에서 left, right context를 모두 참조하여 unlabeled text로부터 deep bidirectional representations를 학습하도록 디자인되었다.
그 결과 pretrained BERT model에 하나의 output layer만 추가하여 fine-tuning을 하여도 다양한 task에서 최고의 성능을 내는 모델을 만들 수 있다.
Introduction
Language model pretraining은 다양한 NLP task에서 매우 효과적이었다. Pretrained language repregentation을 down stream에 적용하는 방법은 feature-based와 fine-tuning 2가지가 있다.
ELMo와 같은 feature-based 방식은 pre-trained representations을 추가적인 feature로 사용하는 task-specific architectures를 사용한다. GPT와 같은 fine-tuning 방식은 pre-trained parameters 전체를 간단하게 미세조정하는 방식이다.
현재의 fine-tuning 방식은 pre-trained representations의 힘을 제한한다고 생각한다. 주요한 한계는 unidirectional 방식으로 학습한다는 것이다. 예를 들어, GPT에서는 left-to-right 아키텍쳐로 인해 self-attention layer에서 모든 토큰이 오직 이전 토큰만 참조 할 수 있다.
본 논문에서는 fine-tuning 방식의 BERT 모델을 제안한다. BERT에서는 masked language model(MLM) objective를 통해 unidirectional 문제를 해결하였다. MLM은 input tokens 중 일부를 랜덤하게 masking하고 이를 예측하는 방식이다. 이를 통해 MLM은 left, right context를 모두 학습할 수 있다. 또한 next sentence prediction(NSP) 방식을 통해 text pair에 대해서도 학습을 한다.
BERT
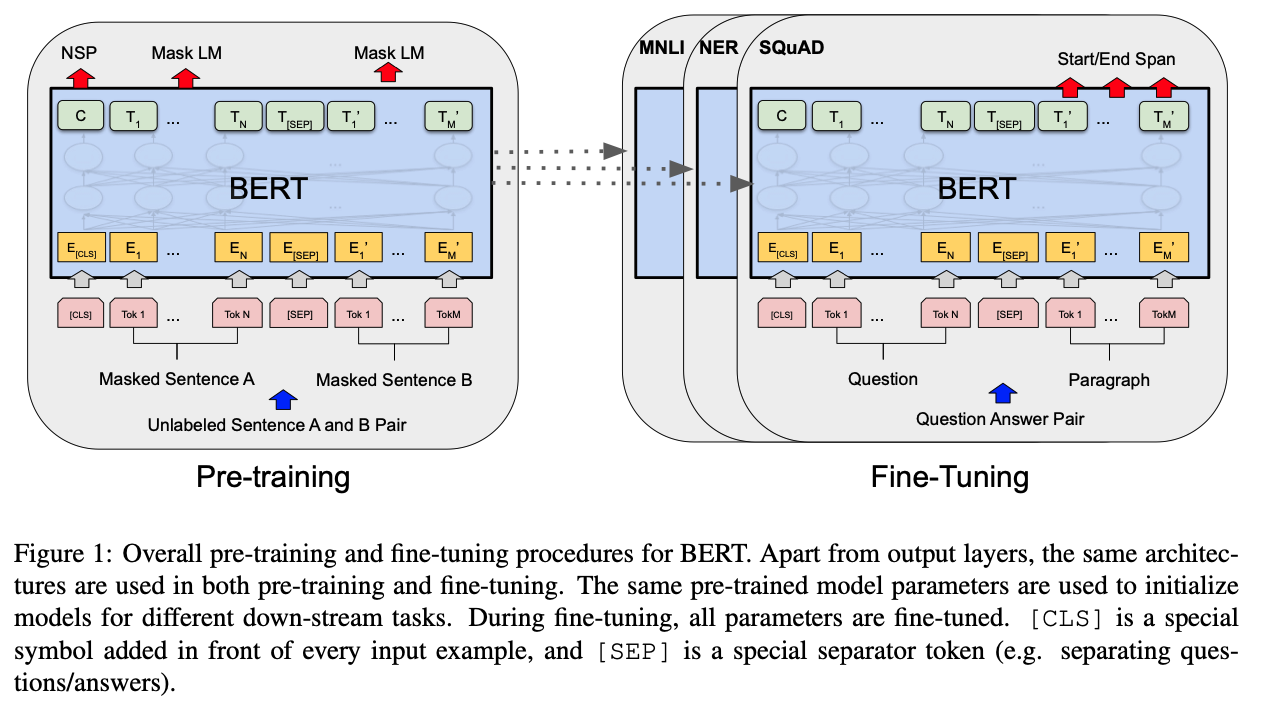
BERT는 pre-training과 fine-tuning 두 단계로 학습을 한다. pre-training 단계는 unlabeled data를 이용해 학습을 하고, fine-tuning 단계에서는 downstream task에 대해 pre-trained parameters를 이용하여 labeled data를 미세조정한다.
BERT의 특징은 여러가지 task를 처리할 수 있는 통합 아키텍처라는 것이다.
Model Architecture
BERT의 multi-layer bidirectional transformer encoder로 이루어져 있다. layers의 수는 L, hiden size는 H, self-attention heads는 A로 표기한다.
- $BERT_{BASE}$ : L=12, H=768, A=12, Total Parameters=110M
- $BERT_{LARGE}$ : L=24, H=1024, A=16, Total Parameters=340M
Input/Output Representations
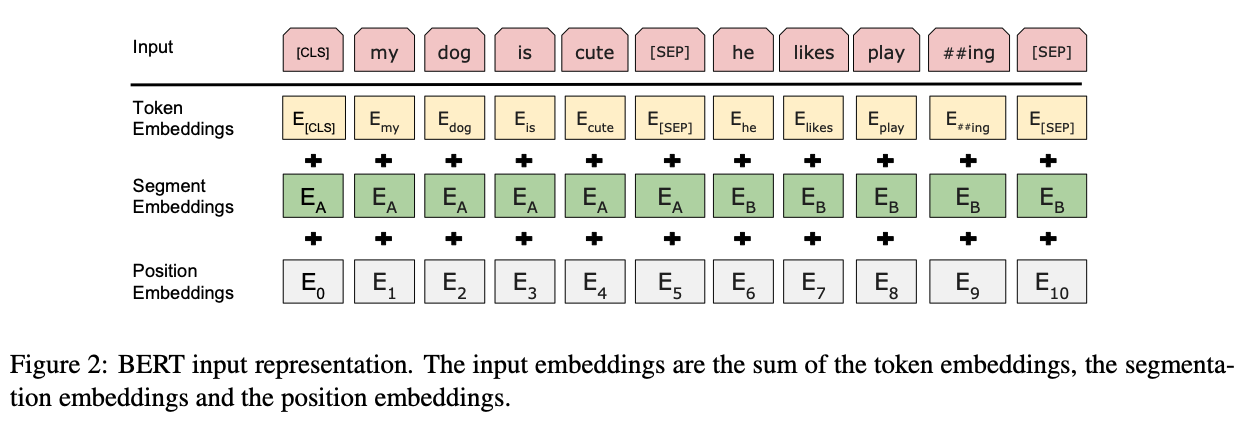
BERT를 이용하여 다양한 task에 적용하기 위해, single sentence와 sentence pair를 모두 표현할 수 있도록 input을 구성하였다. 본 논문에서 말하는 sentence는 연속적인 문장의 임의의 범위이며, 한 문장일 수도 있고 두 문장이 합쳐져 있을 수도 있다.
WordPiece를 이용하여 30,000개의 token을 만들어 사용하였다. 첫번째 token은 항상 special classification token([CLS])이며, classification task에서 aggregate sequence representations로 사용된다.
sentence pairs는 하나의 sequence로 합쳐지며, sentence pairs를 구별하는 2가지 방법이 있다. 첫번째는 special token([SEP])를 사용하는 것이고, 두번째는 모든 토큰에 대해 sentence pair중 어디에 속하는지를 표시하는 embedding을 추가하는 것이다.
위 그림에서 보여지듯이, input embeddings는 E, [CLS]의 final hidden vector는 C, i번째 token의 hidden vector는 T로 표기하였다.
input representation은 token, segment, position embeddings를 summing하여 만들어진다.
Pre-training BERT
전통적인 left-to-right, right-to-left model을 사용하지 않고 Masked LM과 Next Sentence Prediction 방법을 이용하여 학습을 한다.
Task #1: Masked LM
deep bidirectional representation을 학습하기 위해 input token의 일부를 랜덤하게 masking을 하고 이를 예측한다. 이것을 masked LM(MLM)이라고 한다. 모든 실험에서 전체 WordPiece tokens 중 15%를 masking하였다. denoising auto-encoders와 다르게 전체 input을 재구성하는 것이 아니라 masked words를 예측한다.
MLM을 통해 bidirectional pre-trained model을 학습하였으나, pre-training과 fine-tuning 단계 사이의 mismatch가 존재한다. [MASK] token이 fine-tuning 단계에서는 나타나지 않는다는 것이다. 이를 완화시키기위해 15%의 token 중 80%는 masking을 하고, 10%는 랜덤 token으로 교체, 10%는 변경하지 않고 그대로 둔다.
Task #2: Next Sentence Prediction (NSP)
Question Answering, Natural Language Interface와 같이 두 문장 사이의 관계를 학습하는 task를 위해서 next sentence prediction을 수행한다.
sentence A와 B를 선택할때, 50%는 실제로 연결되는 A와 B를 선택하고, 나머지 50%는 랜덤하게 선택한다. 연결되는 경우는 IsNext, 연결되지 않는 경우는 NotNext로 라벨링한다. Figure1에서 볼수있듯이 NSP를 위해 C가 사용된다.
Pre-training data
BooksCorpus(800M words)와 English Wikipedia(2,500M words)를 사용하였고, Wikipedia에서는 lists, tables, headers를 제외하고 오직 text passages만 사용하였다. long contiguous sequences를 위해서는 document-level의 데이터셋을 사용하는 것이 중요하다.
Fine-tuning BERT
fine-tuning은 input과 ouput만 적절히 만들어주면 다양한 downstream task에 적용이 가능하다.
output의 token representations는 sequence tagging, question answering과 같은 token level task를 위해 사용되고, [CLS] representation은 entailment, sentiment analysis와 같은 classification을 위해 사용된다.
fine-tuning은 pre-training과 비교해서 상대적으로 적은 비용으로 학습할 수 있다. 본 논문의 모든 결과는 TPU에서는 1시간, GPU에서는 몇 시간이면 결과를 볼 수 있다.
Ablation Studies
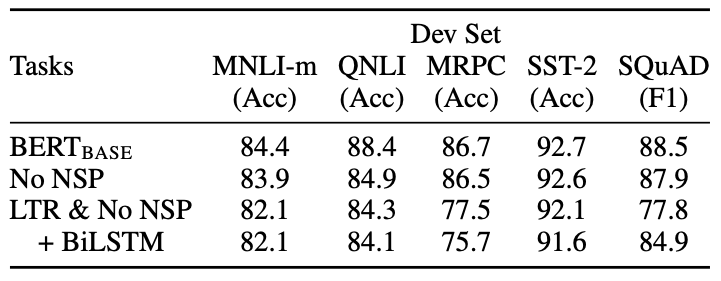
Effect of Pre-training Tasks
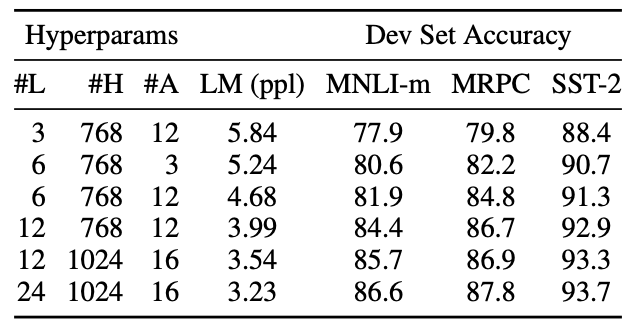
Effect of Model Size
Feature-based Approach with BERT