[논문리뷰] Convolutional neural networks for sentence classification
Contents
Abstract
pretraind word vector와 CNN을 sentence classification task에 적용하여 좋은 결과를 얻음
Introduction
이번 논문에서는, unsupervised neural language model을 통해 학습한 word vector를 이용하여 cnn을 학습한다.
word vector는 google news 천억 단어로 학습되었다. (https://code.google.com/p/word2vec)
먼저 word vector는 static하게 놔두고, 다른 파라미터만 학습을 하였다.
간단한 튜닝을 통해서 많은 benchmark에서 좋은 성능을 얻었다.
Model
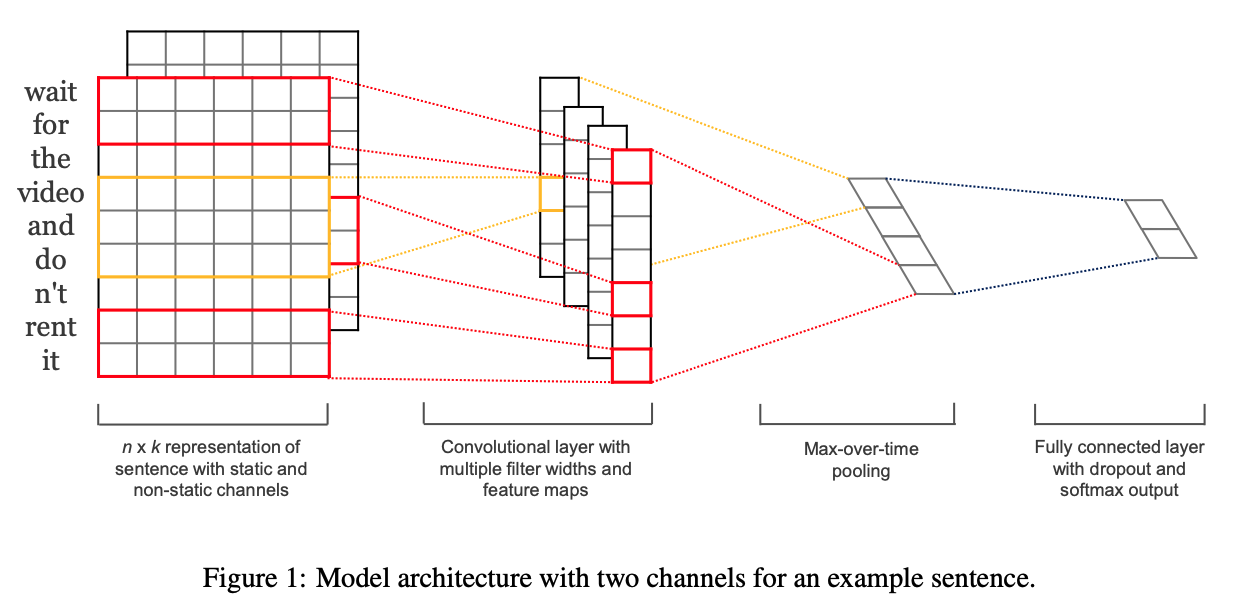
모델 아키텍쳐는 Collobert의 CNN 아키텍쳐에서 조금 변형한 것이다.
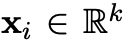
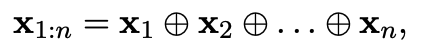
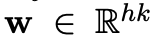
CNN에는 새로운 feature를 만들어내는 filter w가 있고, h개의 단어에 대한 window이다.
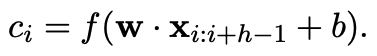
예를 들어, c_i는 윈도우 크기 h에 대한 x_i:i+h-1의 feature이다.
b는 bias, f는 tanh같은 non linear function이다.
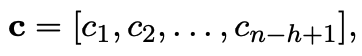
이 filter를 이용해 문장의 feature map c를 만들어낸다.
추출한 feature map에는 max-over-time pooling operation을 적용한다. 이는 가장 중요한 feature를 추출하기 위함이다.
또한 여러개의 filter를 이용해, 여러개의 feature를 추출하고, fully connected softmax layer에 전달하여 probability distribution을 구한다.
모델의 변형 중 하나로, word vector에 대해 2개의 channel을 적용해보았다.
첫번째는 pretrained word vector를 static하게 놔두는 것이고, 두번째는 pretrained word vector에 fine tuning을 하는 것이다.
각 filter는 2개의 channel에 대해 적용이 되고, feature map c로 합쳐진다.
Regularization
regularization을 위해 l2 norms를 이용한 dropout을 적용한다.
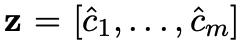
m의 filter에서 추출한 z에 대해
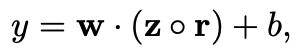
dropout을 적용한 수식이다. r은 masking vector이며, 확률 p를 이용한 random 변수이다.
train 단계에서는 unmasked unit에 대해서만 학습을 한다.
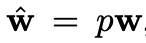
test 단계에서는 학습된 weight vector에 대해 p만큼 scale하여 사용한다.
추가적으로 l2 norms를 적용하여, l2 norm을 적용한 w가 특정 constraint 값보다 클때만 적용하였다.
Datasets and Experimental Setup
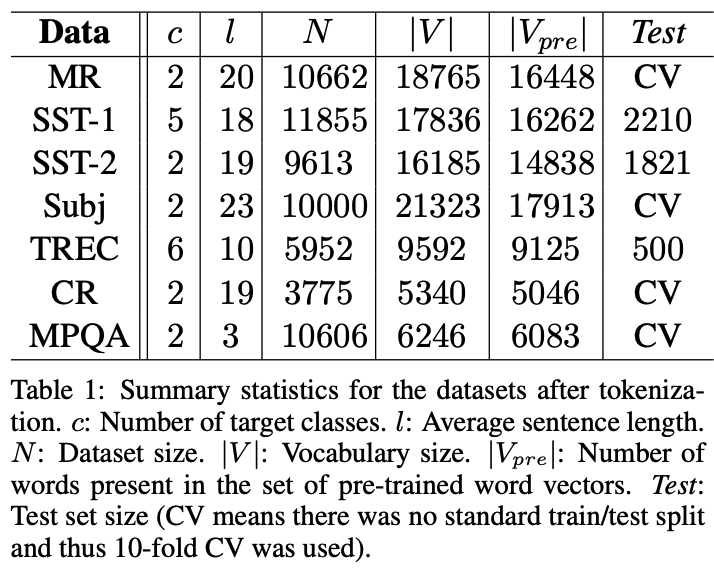
다양한 benchmark에 대해 테스트를 진행하였다.
Hyperparameters and Training
모든 데이터셋에 공통적으로 적용된 하이퍼파라미터
- relu
- filter window size(h) : 3, 4, 5
- 100 feature map
- dropout rate(p) : 0.5
- l2 constraint(s) : 3
- mini batch size : 50
dev셋에 대한 early stopping은 적용하지 않았고, dev셋이 없는 경우는 training data에서 10%를 선택하여 사용하였다.
shuffled mini batch에 대해 adadelta를 이용하여 학습하였다.
Pre-trained Word Vectors
pretrained word vector로 word2vec을 사용하였다.
구글 뉴스 중 천억개의 단어로 학습이 되었고, 300 차원이며 cbow 방식으로 학습되었다.
pretrained word에 없는 단어를 랜덤하게 초기화하였다.
Model Variations
- CNN-rand : 모든 단어는 랜덤하게 초기화하였다.
- CNN-static : word2vec을 이용하였고, word vector는 static하게 유지되고, 다른 파라미터만 학습하였다.
- CNN-non-static : word2vec을 이용하였고, word vector는 fine tuning되었다.
- CNN-multichannel : CNN-static과 CNN-non-static을 합친 모델이다.
Results and Discussion
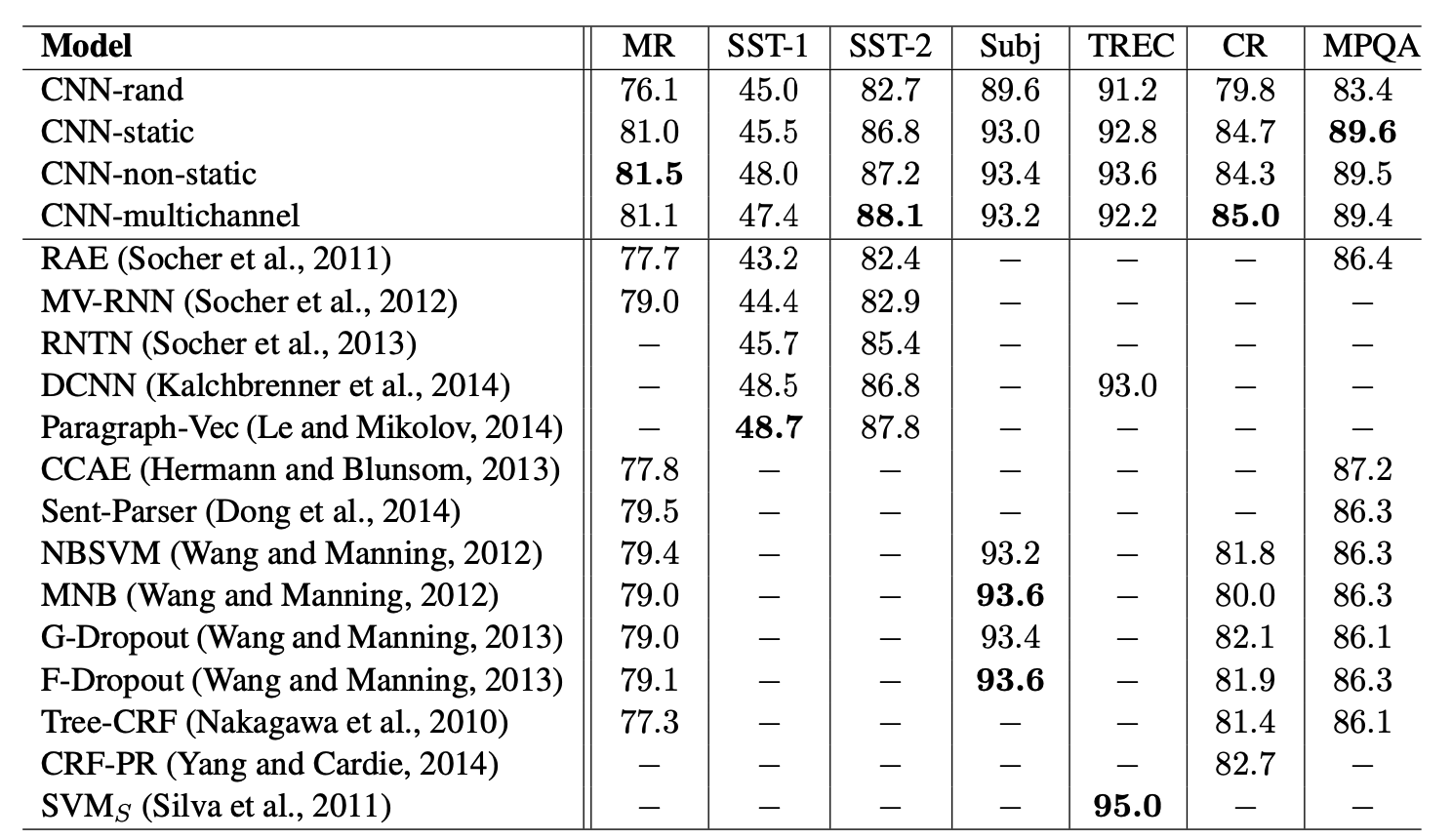
CNN-rand는 좋지 않았지만, pretrained vector를 이용한 방법은 좋은 성능을 보였다.
전체 데이터셋에 대해 pretrained vector를 사용하는 것이 성능이 좋으며, 보편적으로 사용될 수 있음을 보여주었다.
Multichannel vs. Single Channel Models
multichannel이 single channel 보다 더 좋을거라고 기대했지만, single channel이 더 좋은 성능을 보였다. 특히 작은 데이터셋에서 single channel이 더 좋았다.
하지만 multichannel이 더 좋은 성능을 보인 task도 있으며, fine tuning 과정을 정규화하여 더 좋은 성능을 낼 수 있다.
Static vs. Non-static Representations
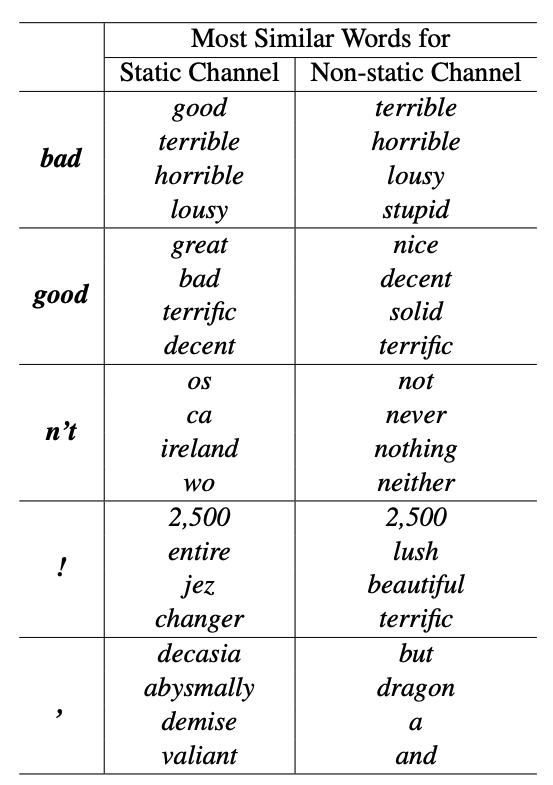
non-static channel을 통해 특정 task에 더 specific하게 fine tuning 할 수 있다.
예를 들어, word2vec에서 bad는 good이랑 가깝지만, SST-2에서는 good이랑 가깝지 않다.
pretrained word에 포함되지 않아 랜덤하게 초기화된 단어들도 fine tuning을 통해 더욱 의미있는 표현으로 학습이 되었다.
느낌표는 과장된 표현(effusive)과 연관이 있고하고, 쉼표는 연결(conjunctive)의 의미가 있다.
Further Observations
- 동일한 아키텍쳐인 Max-TDNN과 비교하여 더 좋은 성능을 보였다. 더 많은 filter와 feature map인 것으로 추정한다.
- dropout은 좋은 regularizer라는 것을 증명했다. 2~4%의 성능향상을 보였다.
- pretrained word에 포함되지 않은 단어에 대해 랜덤하게 초기화할때, pretrained vector와 동일한 분포로 초기화하면 성능 향상이 있었다.
- Collobert가 학습한 pretrained word vector에 대해 실험을 해보았는데, word2vec이 더 좋았다. 아키텍처 문제인지 천억 단어의 구글 데이터셋 영향인지 모르겠다.
- Adadelta는 Adagrad와 비슷한 결과를 보였으나, 더 빨리 학습이 진행되었다.