[논문리뷰] ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
Contents
ABSTRACT
BERT와 같은 masked language modeling(MLM) pretraining methods는 input의 일부 tokens를 [MASK]로 치환하고 이를 원본 token으로 복원하면서 학습을 하는 방식이다. 이런 방식은 매우 좋은 성능을 보였지만, 많은 양의 연산이 필요하다.
이에 대한 대안으로, 보다 효율적인 replaced token detection 방법을 제안한다. small generator를 통해 몇몇 token을 다른 token으로 교체한다. 그리고 각 token이 generator에 의해 교체되었는지 여부를 예측하는 discriminative model을 학습한다.
MLM이 making된 일부 token에 대해 학습하는 것에 비해 제안하는 방법은 모든 input tokens를 학습한다.
그 결과 BERT와 동일한 모델크기, 데이터, 계산으로 훨씬 좋은 성능을 기록하였다. 특히 small 모델에서 강력한 결과가 나왔다.
INTRODUCTION
현재 SOTA 모델들은 일부 token에 대해 masking을 하고 original input을 예측하는 방식으로 학습을 한다. bidirectional representations 학습을 통해 기존 모델들보다 효과적이지만, 일부 token(15%)에 대해서만 학습을 하기 때문에 compute cost가 많이 들게 된다.
이에 대한 대안으로 실제 input과 생성된 input을 구별하며 학습을 하는 replaced token detection을 제안한다. small masked language model에 의해 input token 중 일부 token이 다른 token으로 대체된다. 이렇게 함으로써 BERT에서 발생하는 mismatch를 해결할 수 있다. pre-train 단계에서 [MASK] token이 나타나고, fine-tune 단계에서는 [MASK] token이 나타나지 않는 것을 말한다.
그리고 discriminator가 모든 token에 대해 original인지 replacement인지 predict하면서 학습을 한다. 일부 masking된 token이 아닌 전체 token을 학습하면서 연산 효율이 좋아지게 된다. GAN의 discriminator를 연상시키지만, adversarial하지 않고, maximum likelihood로 학습을 한다.
이 방법을 ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)라고 부른다. 모든 input positions를 학습함으로써 BERT보다 학습속도가 빨리지고, downstream tasks에서 더 높은 성능을 얻을 수 있게 되었다.
ELECTRA는 MLM base인 BERT나 XLNet이 비해, 동일한 크기과 연산, 데이터를 이용해 더 좋은 성능을 보여주었다.
METHOD
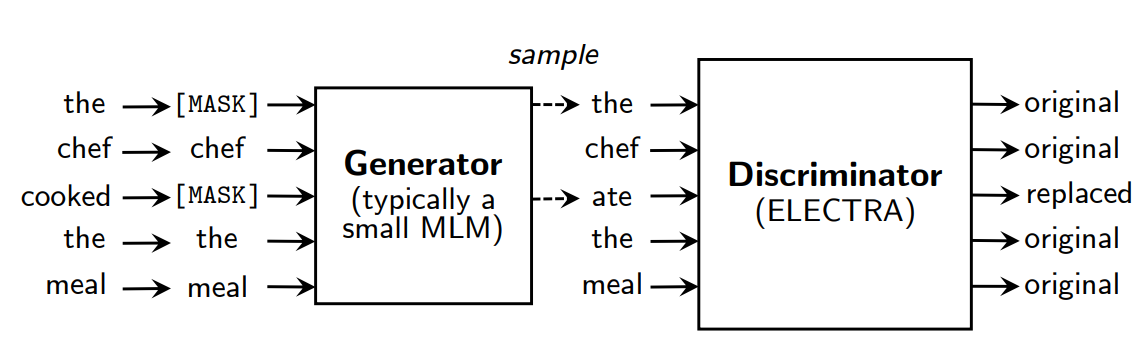
ELECTRA는 generator(G)와 discriminator(D)로 이루어져 있다. 각각은 input token $x = [x_1, …, x_n]$를 contextualized vector representations인 $h(x) = [h_1, …, h_n]$으로 변환하는 encoder로 구성되어 있다.
generator는 softmax를 이용하여 position t에서 특정 token $x_t$를 생성할 확률을 출력한다. $x_t$는 [MASK]인 position이다.
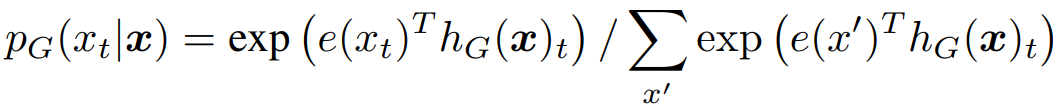
e는 token embedding이며, discriminator는 position t에서 sigmoid layer를 이용하여 $x_t$가 real인지 아닌지 예측한다.
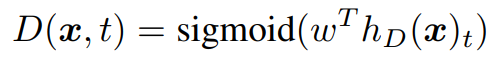
generator는 MLM을 이용해 학습을 한다. 먼저 랜덤하게 positions를 선택하고 [MASK] token으로 교체한다. 이제 generator는 [MASK] token의 원본 값이 무엇이었는지를 예측하는 방법을 학습한다. discriminator는 generator가 생성한 token을 구별하면서 학습을 하게 된다.
수식은 다음과 같다.
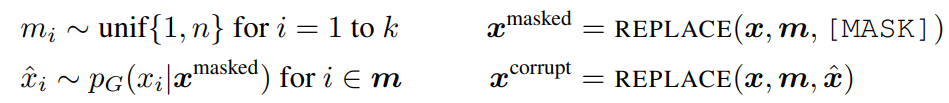
loss function은 다음과 같다.

GAN과 비슷하지만 몇가지 차이점이 있다. 첫째, generator가 correct token을 생성하면 fake가 아닌 real로 간주한다. 둘째, discriminator를 속이기 위해 적대적으로 학습하는 것이 아닌 maximum likelihood로 학습을 한다. generator가 sampling한 것에 대해 back-propagation이 불가능하기 때문이다. reinforcement learning을 해보았지만 maximum likelihood보다 성능이 좋지 않았다. 마지막으로 GAN처럼 input vector에 noise를 추가하지 않는다.
아래와 같이 결합된 loss를 최소화하는 방식으로 학습을 한다.
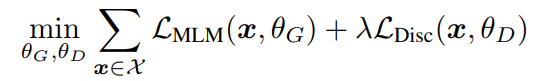
discriminator loss로 generator를 back-propagation 하지 않는다. pre-training 후에는 discriminator를 이용해 downstream task에 적용한다.
EXPERIMENTAL SETUP
model architecture와 대부분의 hyperparameter는 BERT와 동일하게 하였다.
MODEL EXTENSIONS
Weight Sharing
pre-training의 학습 효율을 높이기 위해 generator와 discriminator간에 weights를 sharing하였다. generator와 discriminator의 크기가 같으면 weights를 tie 할 수 있다. 하지만 small generator가 더 효과적인것을 발견하였고, embedding만 share하였다. discriminator의 hidden size와 동일한 크기의 embeddings를 사용하였다. generator의 input과 output token embedding은 BERT처럼 tie하여 사용하였다.
Smaller Generators
generator와 discriminator가 동일한 사이즈라면, MLM을 학습하는 것의 2배의 연산량이 필요하다. 그래서 generator의 layer size를 줄여 smaller generator를 만들었다.
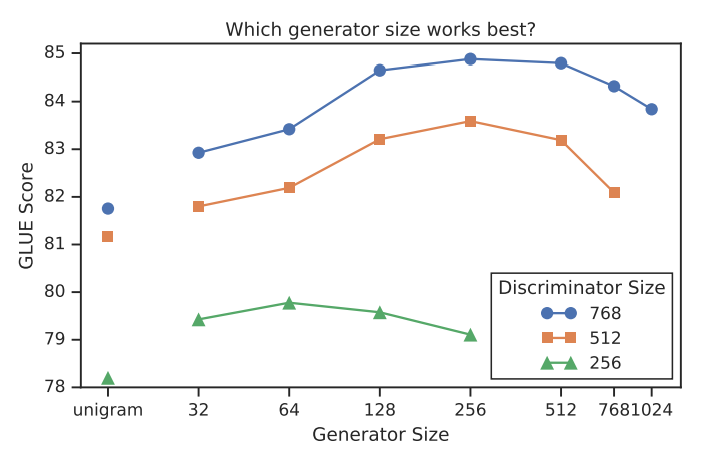
결과적으로 generator의 사이즈가 discriminator 사이즈의 1/4 ~ 1/2일때 가장 좋은 성능을 보였다. generator가 너무 강력한 성능을 보이면 그만큼 discriminator에게 도전적인 과제가 된다고 추측한다.
Training Algorithms
generator와 discriminator를 함께 학습하는 방법 외에 2가지 방법에 대해 추가적으로 실험을 하였다.
- MLM loss를 이용해 n step동안 오직 generator만 학습
- discriminator의 weights를 generator의 weights로 초기화하고, generator는 frozen 후에 n step동안 discriminator만 학습
discriminator의 weights를 초기화하지 않으면 학습이 잘되지 않았고, 아마 generator의 성능이 discriminator의 성능보다 훨씬 좋아졌기 때문이라고 생각한다. 반면에 joint training을 하면 generator가 점점 성능이 좋아지면서 discriminator을 위한 curriculum을 제공한다고 생각한다.
또한 generator를 gan처럼 적대적인 방법으로 학습을 해보았다.
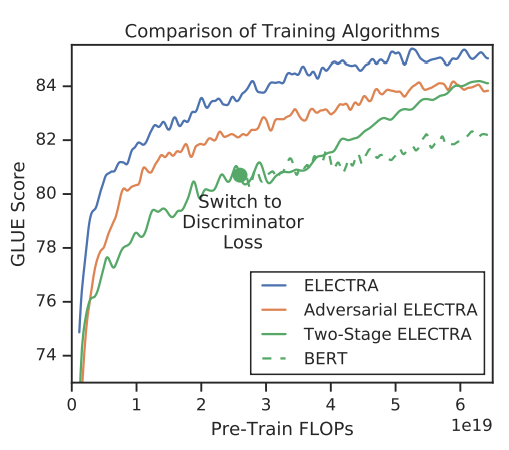
two-stage training 학습 중 objective function을 generative에서 discriminative로 변경하면 성능이 올라가는 것을 확인할 수 있었다. 하지만 파란선의 joint training보다 좋지는 않다.
그 이유에는 2가지 관점에서 찾을 수 있다. 첫째, 매우 큰 action space에서 text를 생성하는 것이 reinforcement learning에서 효율이 좋지 못하기 때문이다. 둘째, 적대적으로 학습된 generator는 낮은 entropy distribution을 보였다.
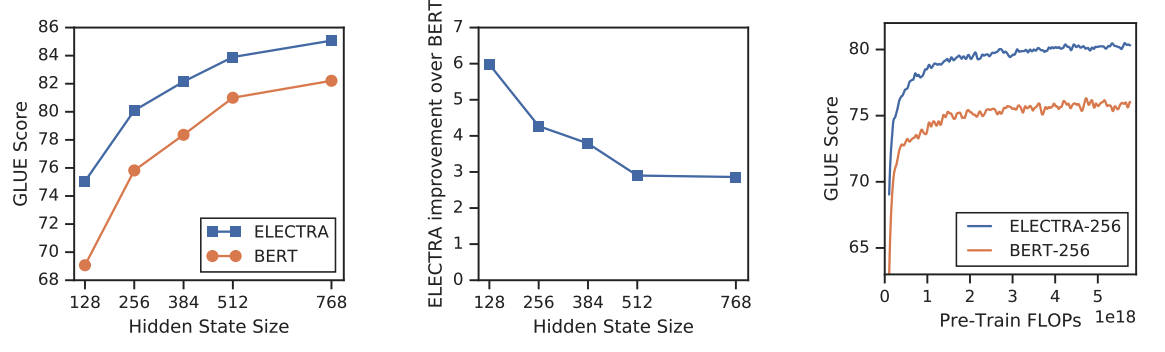
SMALL MODELS
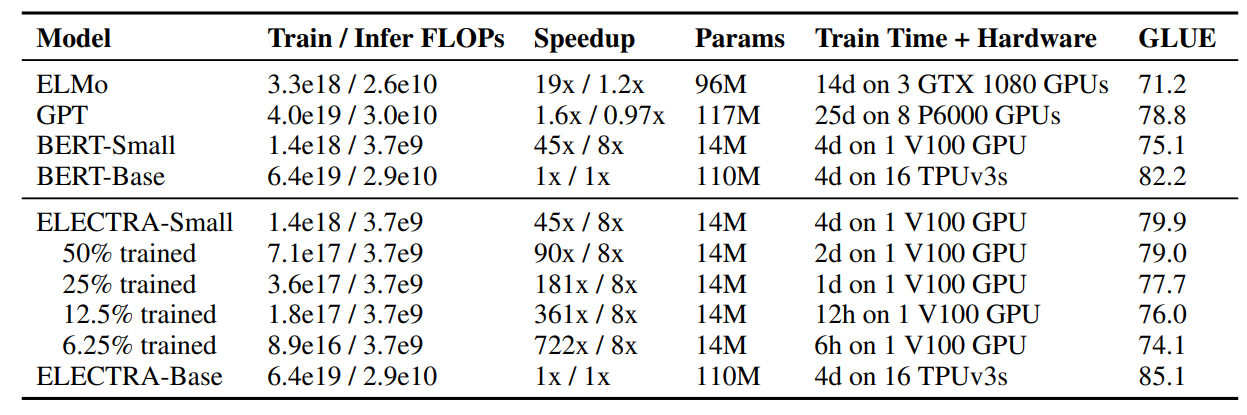
본 논문의 목적은 pre-training의 효율을 높이는 것이기 때문에, 한개의 GPU로 빠르게 학습할 수 있는 small model을 학습해 보았다. BERT-Base에서 sequence(512→128), batch size(256→128), hidden dimension(768→256), token embedding(768→128)로 줄여서 학습을 하였다.
비교를 위해 동일한 hyperparameters의 BERT-Small을 1.5M steps 학습하였다. Electra-Small은 1M steps를 학습하였다.
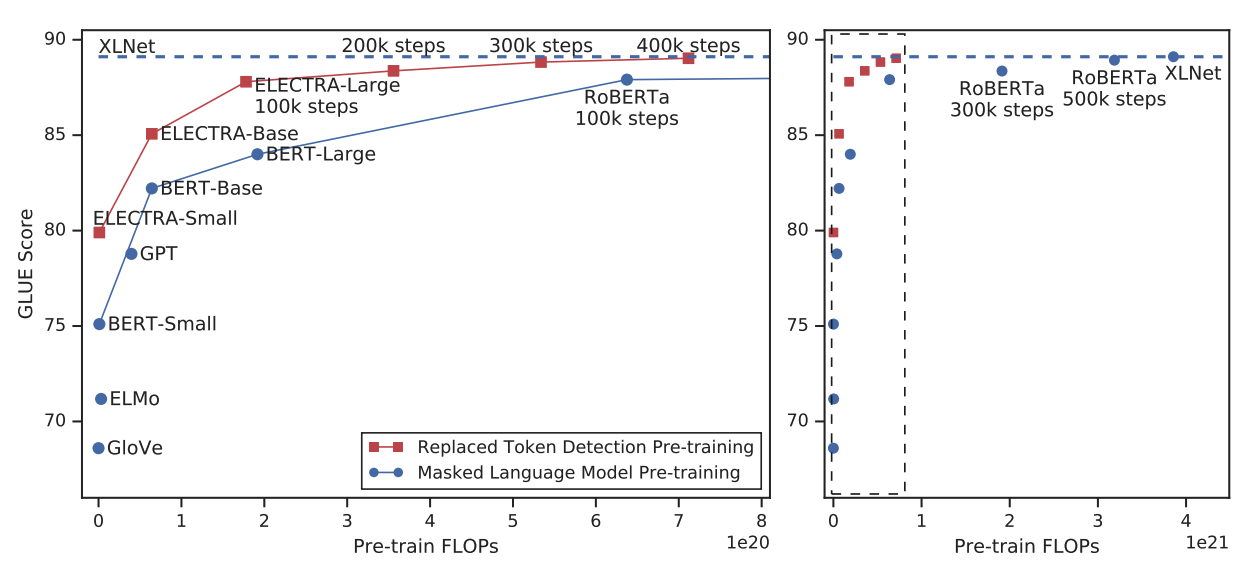
LARGE MODELS
replaced token decection의 효율성을 측정하기 위해 BERT-Large와 동일한 크기의 ELECTRA-Large 모델을 학습하였다. 40만 스텝(RoBERTa의 1/4), 175만 스텝(RoBERTa 수준) 2가지를 학습하였고 batch size는 2048, 데이터는 XLNet의 pretraining data를 사용하였다.
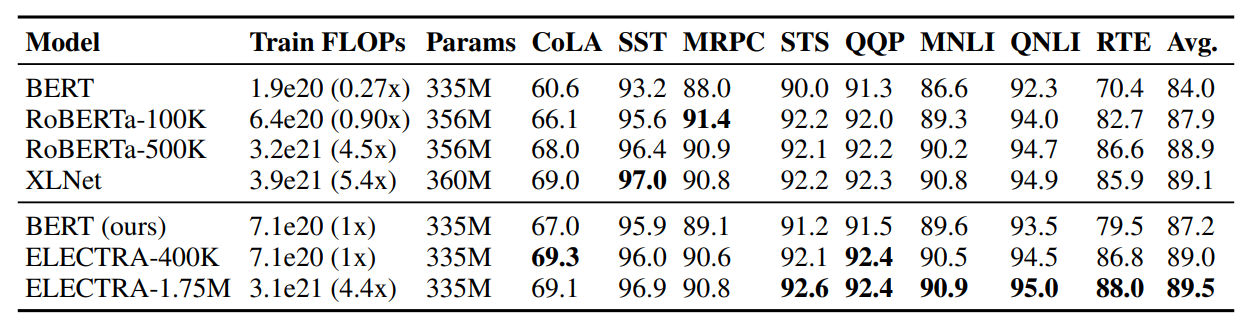
GLUE dev set에 대해 ELECTRA-400K가 RoBERTa와 XLNet과 비슷한 성능을 보였다. ELECTRA-1.75M는 더욱 좋은 성능을 보였으며, 연산량은 여전히 더 적다.
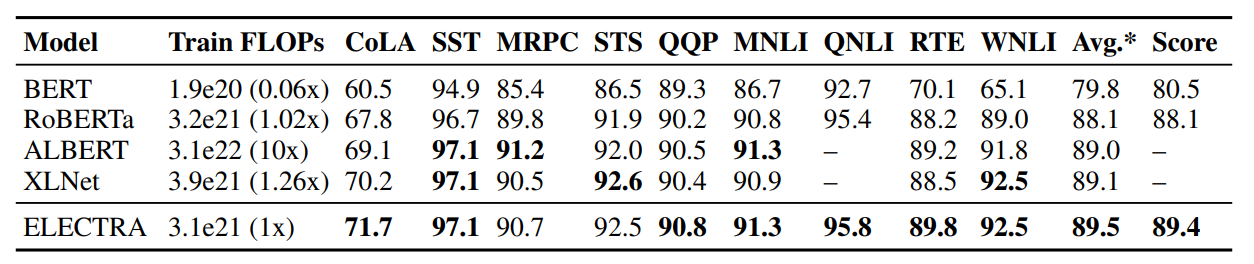
GLUE test set에서도 여전히 좋은 성능을 보인다.
EFFICIENCY ANALYSIS
MLM에 비효율이 있다고 언급하였는데, ELECTRA의 효율에 대해 명확히 이해하기 위해 추가 실험을 진행하였다.

-
ELECTRA 15% : 전체 input 중 masking된 token(15%)에 대해서만 discriminator loss를 계산한다.
⇒ masking된 subset에 대해서만 학습하는 것 보다 전체 input에 대해 학습하는 것이 효과적이다.
-
Replace MLM : MLM과 동일하지만, [MASK] token 대신 generator가 만든 다른 token을 input으로 사용한다.
⇒ BERT보다 나은 성능을 보인것으로 보아, BERT의 making token mismatch 문제로 인해 성능 저하가 있을 수 있다는 것을 유추할 수 있다.
-
All-Tokens MLM : Replace MLM과 동일하지만, mask된 token이 아닌 전체 input token에 대해 예측을 한다.
⇒ BERT와 ELECTRA의 중간 모델인 All-Tokens MLM이 ELECTRA에 가장 근접한 성능을 보였다.
또한 ELECTRA가 BERT에 비해 학습이 더 빠른 것을 확인할 수 있었고, 특히 작은 모델일수록 더 효과적이었다.