[논문리뷰] Deep contextualized word representations
Contents
ABSTRACT
본 논문에서는 단어 사용의 문법적, 의미적 복잡성과 언어적 맥락에 따라 어떻게 달라지는지에 대해 모델링하는 deep contextualized word representations를 소개한다.
word vector는 대용량의 corpus를 이용한 bidirectional language model(biLM)에 의해 학습된다.
이 word vector는 다른 모델에 쉽게 추가하여 사용할 수 있으며, 6개의 NLP task에서 sota의 성능을 보였다.
INTRODUCTION
많은 neural language understanding model에서 pretraind word representations는 중요한 요소이다. 하지만 단어 사용의 복잡성과 문맥적 특성으로 인해 높은 퀄리티의 representations를 얻는 것은 어려운 일이다. 본 논문에서는 이러한 특성을 고려하고, 기존 모델에 쉽게 적용할 수 있는 deep contextualized word representation을 제안한다.
전통적인 word embeddings와 달리 sentence 전체를 고려하는 representations를 학습한다. 또한 결합된 language model objective를 이용한 bidirectional LSTM에서 생성된 vector를 사용한다. 이러한 이유로 이 모델을 ELMo (Embeddings from Language Models)라고 표현한다.
ELMo는 biML의 모든 layers를 다 사용한다. top layer만 사용하였을때보다 모든 layers를 사용하는 것이 더 좋은 성능을 보인다. 높은 layer는 context-dependent한 부분을 학습하며, 낮은 부분은 syntax적인 부분을 학습하게 된다.
ELMo: Embeddings from Language Models
Bidirectional language models
N개의 token인 $(t_1, t_2, …, t_n)$을 가지는 sequence가 주어졌을때, forward language model은 $(t_1, …, t_{k-1})$를 이용하여 $t_k$의 확률을 모델링 함으로써 sequence의 확률을 계산한다.
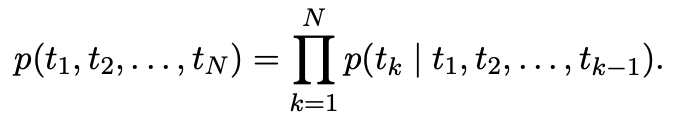
context-independent token인 $x_k^{LM}$을 L개의 LSTM layer에 통과시킨다. 각각의 k position에서 각 LSTM은 context-dependent representation인 $\vec h_{k,j}^{LM}$을 출력한다. LSTM의 top layer의 output인 $\vec h_{k,L}^{LM}$을 softmax layer에 통과시켜 $t_{k+1}$을 예측하는데 사용한다.
backward language model은 forward language model을 reverse한 것이다.
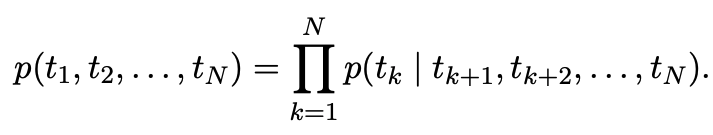
biLM은 forward와 backward를 결합한 것이며 log likelihood를 최대화하도록 학습한다.
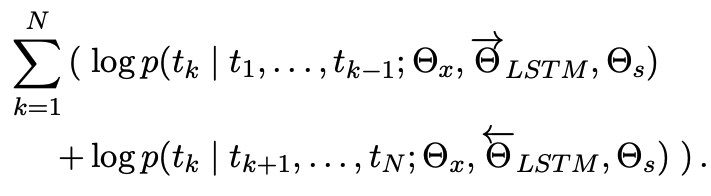
token representations와 softmax는 forward/backward에서 동일한 parameter를 사용하고, LSTM에서는 각각 사용한다.
ELMo
ELMo는 전체 L layer에 대해 forawrd, backward representations을 결합한 형태로 표현한다.
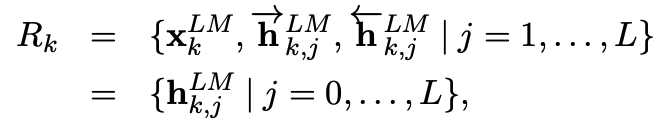
이렇게 계산된 표현을 이용해 각 downstream task에 대해 전체 biLM layer의 가중치를 계산하여 모델링을 하게 된다.
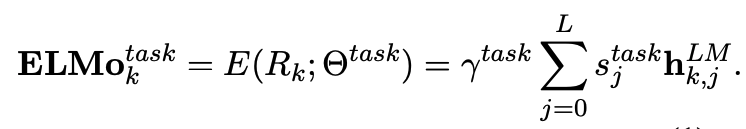
$s^{task}$는 softmax-normalized weights로 어떤 layer에 집중해야되는지를 나타내며, $γ^{task}$는 전체 ELMo vector 크기를 결정하는 역할을 한다.
Using biLMs for supervised NLP tasks
간단한 방법으로 pretrained biLM를 supervised NLP task에 결합하여 성능을 높일 수 있다. context-independent token $x_k$와 freeze된 ELMo vector를 결합하여, task architecture의 input으로 사용한다.
Pre-trained bidirectional language model architecture
pre-trained biLM은 양방향 training을 하며, lstm layers 사이에 residual connection을 추가하였다.
최종 모델은 4096 unit을 가지는 bi-LSTM 2개와 512 dimension의 projections, residual connection으로 이루어져 있다. context insensitive type representation은 2048 character의 n-gram convolution filter와 2개의 highway layers를 사용한다.
Evaluation
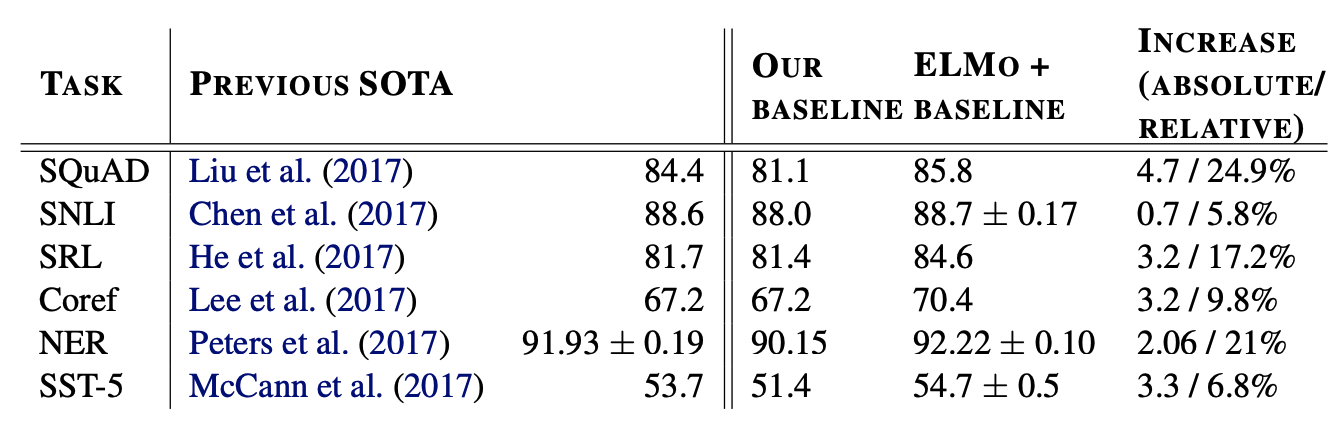
ELMo를 추가한 결과 새로운 SOTA를 달성하였다.
Analysis
Alternate layer weighting schemes
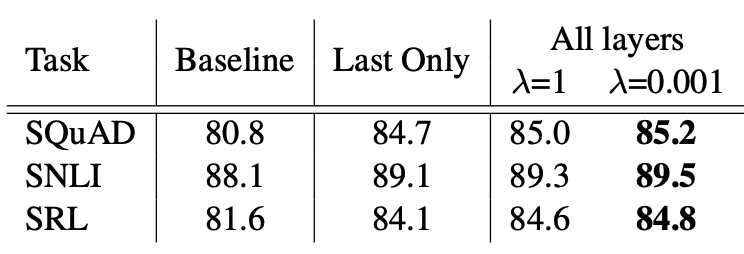
weight를 다양하게 만든 것이 평균을 사용하는 것보다 성능이 좋은 것을 확인할 수 있다.
Where to include ELMo?

What information is captured by the biLM’s representations?

glove는 play에 대해 주로 sports에 관련된 것들만 유사어로 추출이 되지만, biLM에서는 sports 뿐만 아니라 연극에 관련된 것도 추출이 되는 것을 볼 수 있다. ELMo는 word vector에서 가지고 있지 않은 문맥 정보를 가지고 있는 것을 알 수 잇다.
Sample efficiency
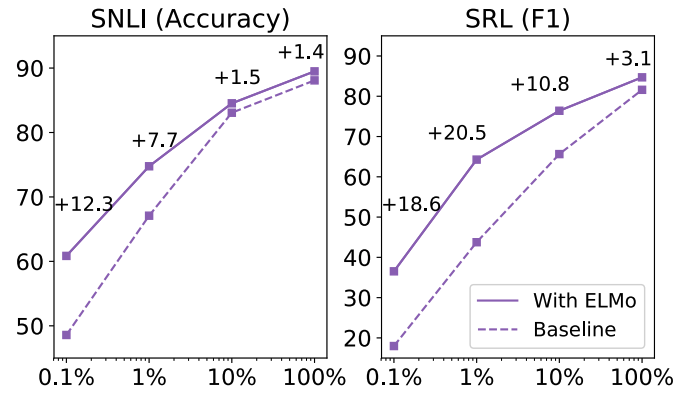
ELMo를 사용하였을 때 더 적은 training step과 dataset을 사용하여도 비슷한 성능 수준에 도달할 수 있다.