[논문리뷰] Improving language understanding by generative pre-training
Contents
ABSTRACT
natural language understanding에는 textual entailment, question answering, document classification 등등 넓고 다양한 task들이 존재한다.
unlabeled data는 매우 많지만, 특정 task를 위한 labeled data는 드물기 때문에 각 task별로 좋은 성능의 모델을 만드는 것이 쉽지 않다.
그래서 다양한 unlabeled text를 이용하여 generative pre-training을 수행하여 language model을 만들고, 각 tasks에 맞게 discriminative fine-tuning하는 방법을 소개한다.
결과적으로 각각 task를 위해 만들어진 아키텍처에 비해 더 좋은 성능을 보였다.
INTRODUCTION
딥러닝 방법은 많은 양의 labeled data를 필요로 한다. 하지만 label 작업은 많은 시간과 돈이 소요되므로 unlabeled data를 통해 학습을 하는 것은 매우 중요하다.
ublabeled data에서 중요한 정보를 학습하는 것에는 2가지 어려움이 존재한다.
첫째는 어떤한 optimization objectives가 text representations를 학습하는데 효율적인지 불명확하다는 것이고, 둘째는, 학습한 representations를 target task에 transfer하는 가장 효율적인 방법에 대한 합의가 없다는 것이다.
본 논문에서는 unsupervised pre-training 단계와 supervised fine-tuning 단계를 이용한 semi-supervised 방법을 제안한다. 이를 통해 universal representation을 학습하고 조금의 변형으로 다양한 task에 적용한다. 모델 아키텍처로는 Transformer를 사용한다.
Framework
Unsupervised pre-training
unsupervised corpus의 tokens에 대해 likelihood를 최대화하는 standard language modeling objective를 사용한다.
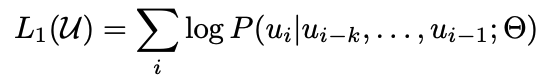
k는 context window size이며, P는 neural network의 parameter Θ를 사용하여 모델링된다. parameter는 stochastic gradient descent를 사용해 학습한다.
multi-layer Transformer decoder를 아키텍처로 사용한다. 먼저 input context token에 대해 multi headed self-attention을 수행하고, position-wise feedforward layer를 통해 target token에 대한 output distribution을 생성한다.
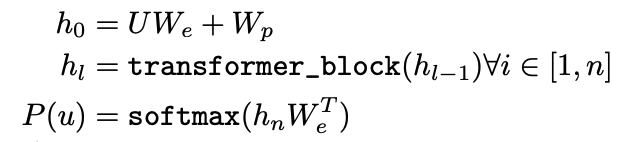
$U = (u_-k,…,u_-1)$은 tokens의 context vector이며, n은 layer의 개수, $W_e$는 token embedding matrix, $W_p$는 position embedding matrix이다.
Supervised fine-tuning
pre-training 이후 target task에 대해 parameter fine-tuning 단계를 진행한다. fine-tuning 단계에서 사용하는 labeled dataset은 input tokens의 sequence와 그에 대한 label y로 이루어져 있다고 가정한다.
input은 마지막 transformer block의 activation h를 얻기 위해 pre-trained model에 입력되고, 추가적인 linear output layer를 통해 y를 예측한다.
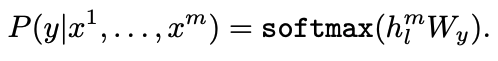
이렇게 함으로써 아래 objective를 최대화 할 수 있다.
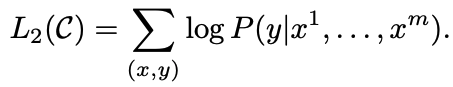
language modeling을 보조지표로(auxiliary objective) 포함하는 것이 fine-tuning 단계에서 generalization을 향상시키고 convergence를 가속화한다는 것을 발견하였다.
weight λ를 이용해 아래 수식에 대해 최적화를 수행한다.
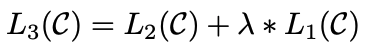
종합하자면 fine-tuning 단계에서 추가되는 parameters는 $W_y$와 embeddings를 위한 delimiter tokens이다.
Task-specific input transformations
text classification과 같은 tasks는 위에서 언급한 방식으로 fine-tuning이 가능하다. 하지만 textual entailment나 question answering과 같이 여러개의 문장이 입력으로 필요한 경우에는 조금의 변형이 필요하다.
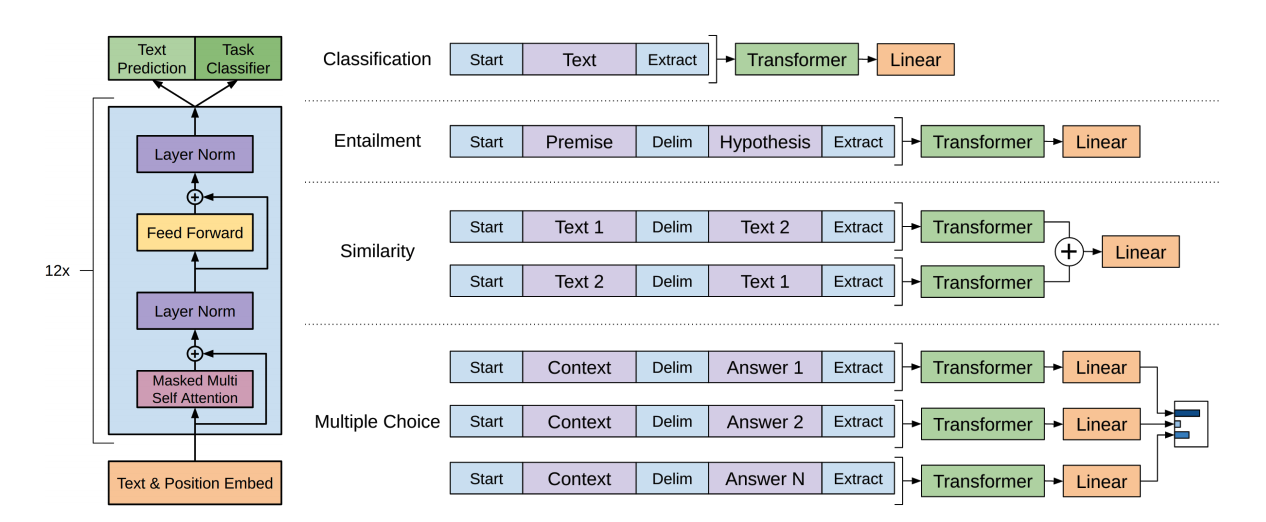
- Textual entailment
- premise p와 hypothesis h를 delimiter token을 이용하여 연결한다.
- similarity
- 두 문장에는 고유한 순서가 없다. 이를 반영하기 위해 가능한 모든 문장의 순서를 input sequence로 만들고 각각 representations를 만들어서 add한다.
- Question Answering and Commonsense Reasoning
- document, question, answer를 연결하여 각각 학습하고, softmax를 통해 output distribution을 구한다.
Experiments
Unsupervised pre-training
pre-train 단계에서는 다양한 분야의 7,000권의 책으로 이루어진 BooksCorpus dataset을 사용한다. 연속적인 텍스트가 많이 존재하여 long-range information을 학습할 수 있다.
Supervised fine-tuning
fine-tuning에 사용한 dataset은 아래와 같다.

다양한 NLI tasks에서 성능 향상이 크게 이루어졌다.
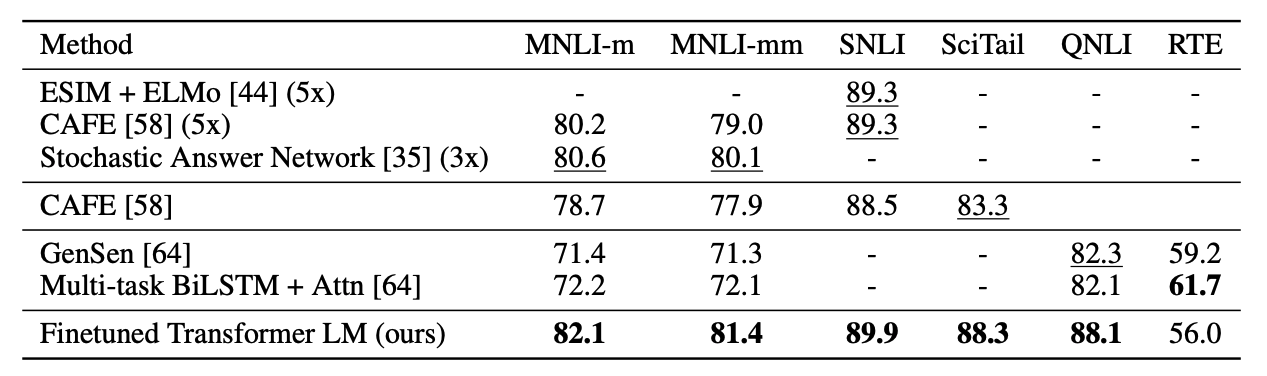
question answering과 commonsense reasoning에서도 좋은 성능을 보였다.
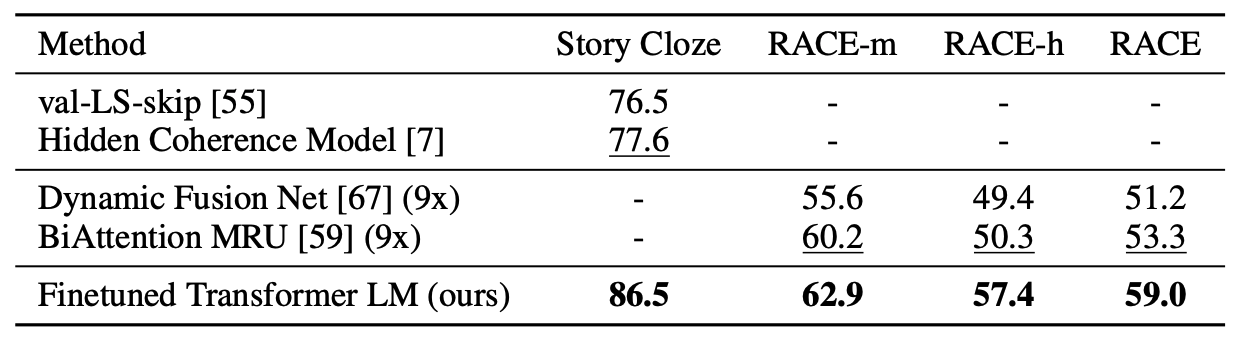
classification과 semantic similarity에서도 sota를 갱신하거나 이전 sota모델에 근접한 성능을 보였다.
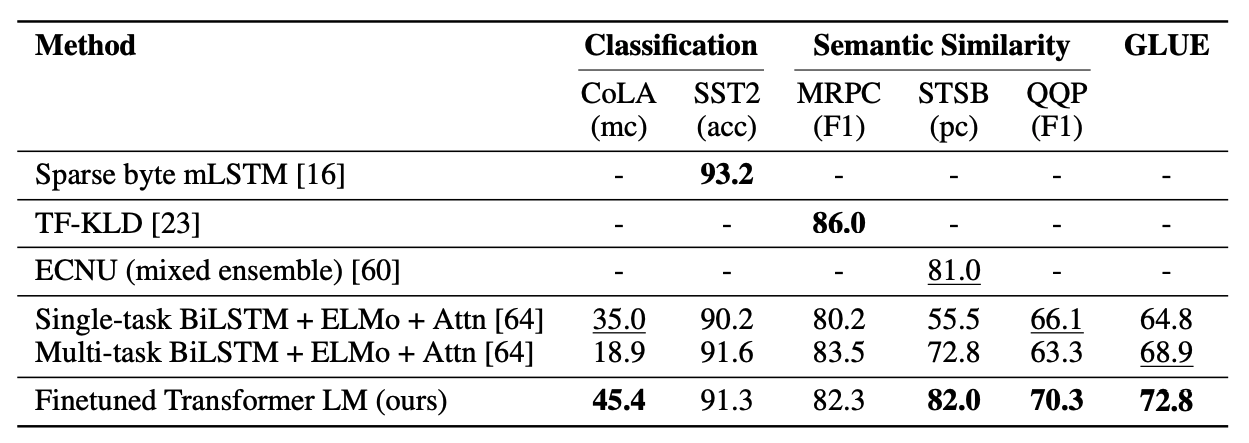
Analysis
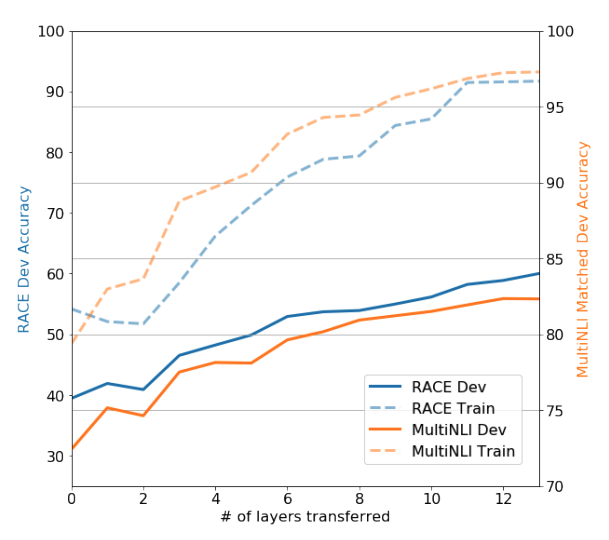
Impact of number of layers transferred
transformer layer의 수가 성능에 얼마나 영향을 미치는지 실험을 하였고, layer의 수가 증가할때마다 성능이 향상되는 것을 확인할 수 있다.
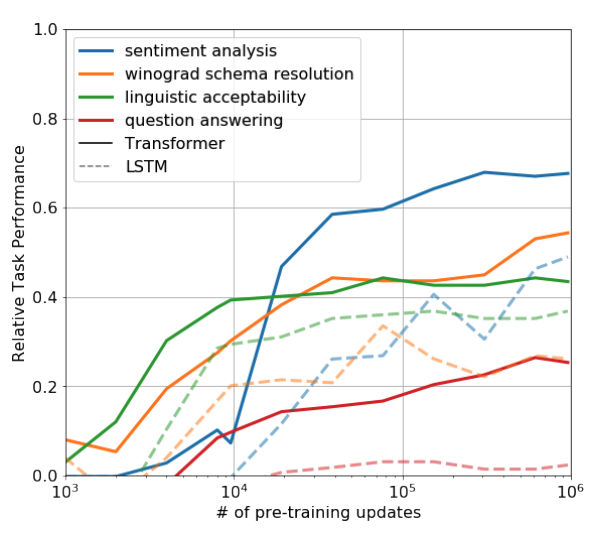
Zero-shot Behaviors
pre-training이 진행됨에 따라 각 tasks의 성능이 향상되는 것을 확인할 수 있다. 또한 transformer를 사용하였을 때 LSTM 보다 성능이 좋을 것을 확인할 수 있다.
Ablation studies
QQP, MNLI, QNLI, RTE와 같이 dataset의 규모가 큰 경우 auxiliary objective를 사용하는 것이 성능에 좋고, dataset의 규모가 작은 경우는 제외하는 것이 성능에 더 좋았다. pre-training을 하지 않았을 경우는 성능이 매우 좋지 않았다. 또한 transformer를 사용하는 것이 LSTM을 사용하는 것 보다 모든 경우에 더 성능이 좋았다.