[논문리뷰] RoBERTa: A Robustly Optimized BERT Pretraining Approach
Contents
Abstract
BERT pretraining 할 때 hyperparameters와 training data size가 어떤 영향을 미치는지 재현연구(replication study)를 하였고, BERT는 significantly undertrained라는 것을 발견하였다.
Introduction
ELMo, GPT, BERT, XLM, XLNet과 같은 self-training 방법들은 엄청난 성능향상을 가져왔지만, 어떠한 측면이 성능향상에 영향을 줬는지 정확하게 알기가 어렵다.
BERT를 이용하여 이에 대한 재현연구를 진행하였고, 성능이 향상된 recipe를 제안한다.
- 더 큰 batch와 더 많은 data를 이용하여 더 오래 학습을 진행한다.
- next sentence prediction을 수행하지 않는다.
- longer sequence에 대해 학습한다.
- masking pattern을 동적으로(dynamically) 변경한다.
- CC-NEWS라고 불리는 매우 큰 새로운 데이터셋을 구축하였다.
Experimental Setup
Implementation
original BERT의 주요 hyperparameter를 그대로 사용하였고, peak learning rate와 warm up step만 다르게 설정하였다. 추가로 Adam epsilon term이 학습에 매우 민감하다는 것을 발견하였고, batch size가 클 경우 $\beta_2$를 0.98로 하였을때 안정적으로 향상되었다.
BERT와 달리 random하게 짧은 문장을 넣는 것을 하지 않고, 대부분 full-length에 맞춰 학습하였다.
Data
BERT style의 방법들은 대부분 많은 양의 text를 가지고 학습을 한다. roberta는 160GB의 데이터를 수집하여 학습하였다.
Training Procedure Analysis
BERT base모델과 동일한 설정으로 학습을 진행하였다.
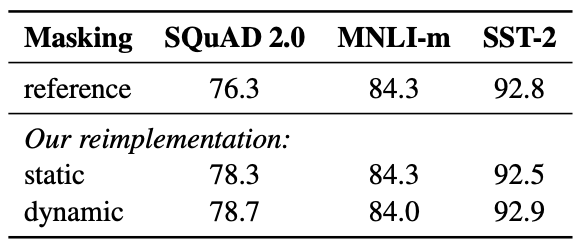
Static vs. Dynamic Masking
original BERT에서는 한번 masking을 수행하여 매 epoch마다 같은 데이터를 학습하게 된다. 이를 static방식이라고 한다. roberta는 학습셋을 10벌을 복제하여 각각 다르게 masking을 하는 dynamic masking을 적용하였고, 총 40epoch를 학습하였다. 각각의 문장은 총 4번 학습하게 된다.
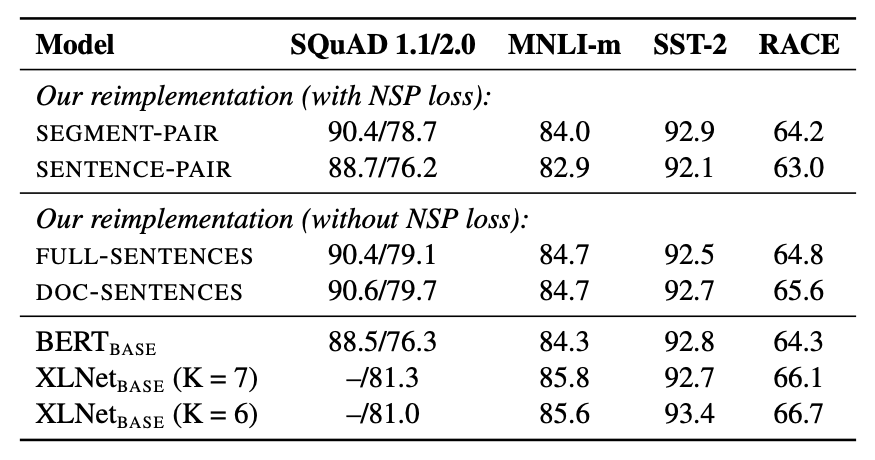
Model Input Format and Next Sentence Prediction
BERT 논문에서는 NSP가 성능 향상에 중요한 요인이라고 하였으나, 최근 몇몇 연구에서는 NSP에 대해 의문을 제기하고 있다.
RoBERTa에서는 4가지 실험을 통해 이를 설명하였다.
- NSP loss 포함
- SEGMENT-PAIR : BERT에서 사용한 original input format
- SENTENCE-PAIR : 한 문서 내에서 연속된 senteces pair 혹은 서로 다른 문서에서 가져온 sentence pair
- NSP loss 미포함
- FULL-SENTENCES : 한 문서 혹은 연속된 문서에서 연속되는 sentences를 추출
- DOC-SENTENCES : 한 문서 내에서만 연속되는 sentences를 추출
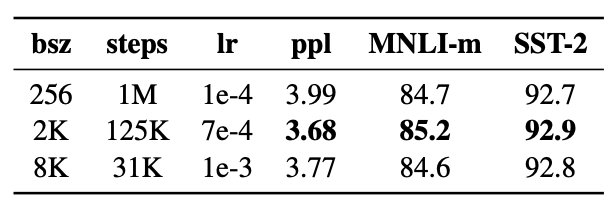
Training with large batches
최근의 연구들에 따르면 batch size를 크게 하는 것이 속도와 성능에 좋다고 한다. BERT 역시 마찬가지이다.
BERT base 세팅인 1M steps에 256 senquences는 125K steps/2K size, 31K steps/8K size와 동일한 연산 크기를 가진다.
Text Encoding
original BERT에서는 heuristic tokenization rules를 이용해 전처리를 한 후 30K 크기의 character level BPE vocabulary를 만들어 사용한다.
RoBERTa에서는 전처리를 하지 않고, 50K 크기의 byte level BPE vocabulary를 사용한다.
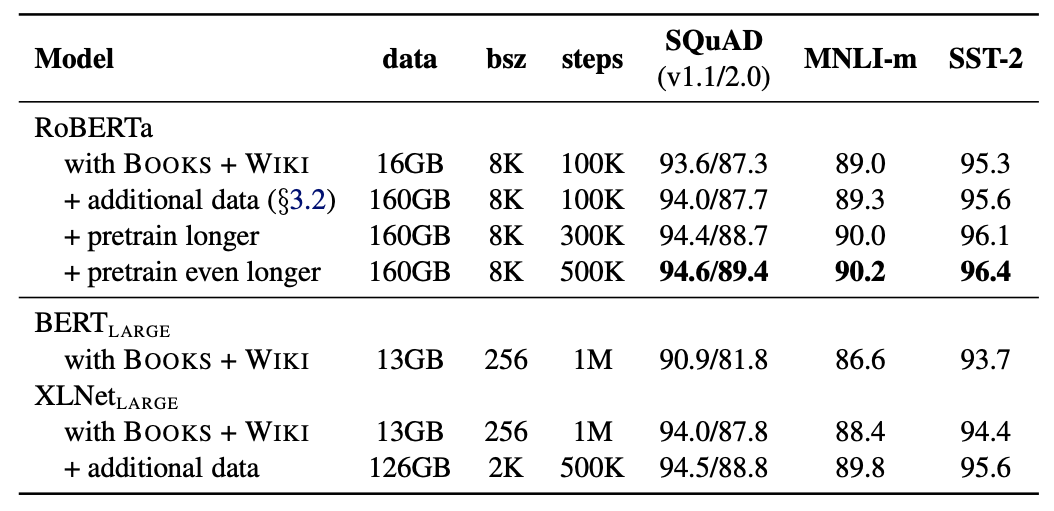
RoBERTa
이전의 내용들은 종합하면 RoBERTa는 dynamic masking, NSP loss가 없는 full-sentences, large mini-batches, large byte-level BPE를 사용한다.
추가적으로 중요한 2가지 요인이 있다. pretraining에 사용되는 data와 data의 학습 횟수이다. 이 두가지 요소의 중요성을 확인하기 위해 BERT LARGE와 동일한 아키텍쳐의 RoBERTa를 학습하여 결과를 비교하였다.