[논문리뷰] Sequence to Sequence Learning with Neural Networks
Contents
Abstract
multi-layer LSTM 구조를 이용하여 sequence를 학습하는 방법을 제안
Introduction
DNN은 speech recognotion, visual object recognition과 같은 어려운 문제들에 대해 매우 좋은 성능을 보여 왔다. 하지만 DNN은 input과 target이 고정된 차원일 경우에만 적용이 가능하기 때문에, machine translation이나 question answering과 같이 길이가 미리 주어지지 않는 문제에 대해서는 적용에 어려움이 있다.
LSTM 구조를 이용하면 sequence to sequence 문제를 해결 할 수 있다. 하나의 LSTM에서는 매 timestep마다 input sequence를 읽어서 vector로 표현하고, 다른 LSTM에서는 vector로 부터 output sequence를 추출하는 방식이다.
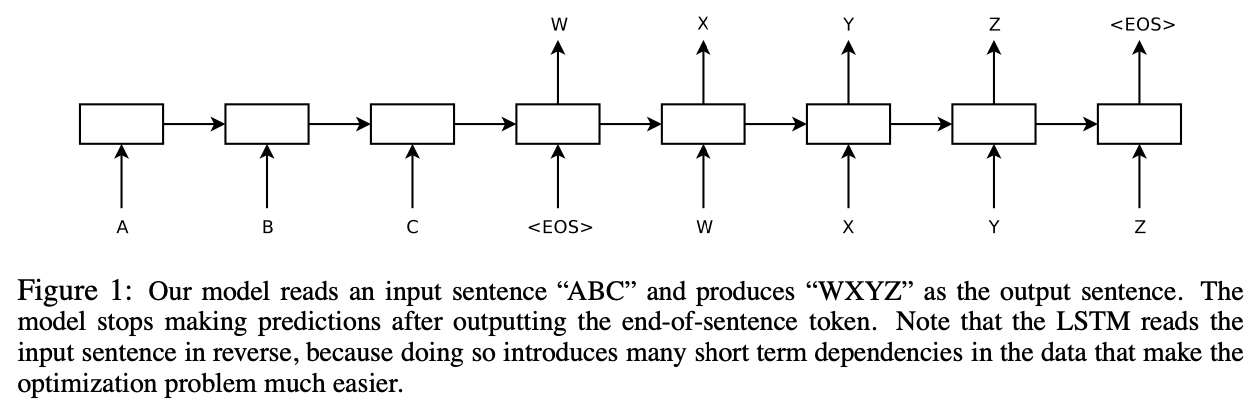
Model
RNN은 input sequence (x_1, …, x_T)가 주어졌을때, output sequence (y_1, …, y_T)를 계산한다.
input과 output sequence의 길이가 다르거나, 복잡한 관계를 가질때는 적용하기가 어렵다.
이를 해결하는 가장 간단한 방법은, 하나의 RNN은 input sequence를 고정된 크기의 vector로 mapping하고, 또 다른 RNN이 이 vector을 target sequence로 mapping 하는 방법이다.
이 방법으로 RNN이 정상적으로 동작은 하지만, long term dependency 문제로 인해 학습이 잘 되지 않을 수 있다.
LSTM은 이 long term dependency를 잘 학습할 수 있는 구조이다.
LSTM의 목적은 input sequence (x_1, …, x_T)와 output sequence (y_1, …, y_T')의 길이가 다를 때, conditional probability p(y_1, . . . , y_T′ | x_1, . . . , x_T)를 측정하는 것이다.
LSTM은 input sequence (x_1, …, x_T)를 이용해 고정된 크기의 v를 구한다. input sequence (x_1, …, x_T)는 LSTM의 마지막 hidden state 값이다.
그리고 LSTM을 이용하여 y_1, …, y_T’의 확률을 구한다. 수식은 아래와 같다.
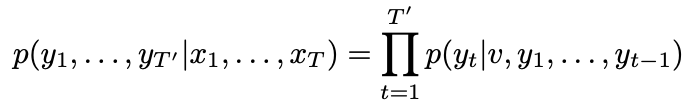
각각의 p(y_t|v, y_1, . . . , y_t−1)는 전체 vocabulary에 있는 단어를 통해 softmax로 표현된다.
각 문장은 “
Figure1에서 표현된 것처럼, input “A”, “B”, “C”, “
실제 모델은 다른 점이 3가지 있다. 첫째는 input과 output을 위한 LSTM이 각각 존재한다. 둘째는 4개의 LSTM를 중첩하여 사용하였다. 셋째는 sequence word 순서를 뒤집어서 input으로 사용하였다.
Experiments
Dataset details
WMT'14(english to french) dataset을 사용하였다. 그 중 12M개의 문장을 학습에 사용하였다.
source 언어에서는 160,000개의 단어, target 언어에서는 80,000개의 단어를 사용하였다.
Decoding and Rescoring
이 실험의 핵심은 크고 깊은 LSTM을 이용해 많은 sentence pair를 학습하는 것이다. source sentence S에 대해 correct translation T의 log probability를 최대화하도록 학습을 하였다.
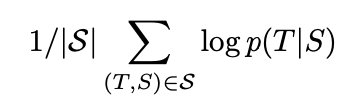
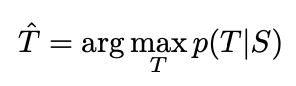
Reversing the Source Sentences
LSTM으로 long term dependency 문제를 해결할 수 있지만, source sentence를 뒤집어서 input으로 사용하면 더 좋은 결과를 낼 수 있다. test perplexity는 5.8에서 4.7로 낮아지고, BLEU score는 25.9에서 30.6으로 증가하였다.
이 현상에 대해 정확하게 설명할 수 없지만, source sentence를 뒤집음으로써, source sentece의 앞쪽에 있는 몇몇 단어들이 target sentece와 가까워지기 때문에 minimal time lag 문제가 해결되고 성능이 향상된 것으로 보고 있다.
Training details
- 4개의 LSTM layer
- LSTM의 layer를 추가할때마다 perplexity가 10% 가까이 줄어들었다.
- 1,000개의 cell
- 1,000 dimensional word embedding
- 160,000개의 input vocabulary
- 80,000개의 output vocabulary
- softmax
- LSTM의 모든 파라미터는 -0.08에서 0.08 사이의 uniform distribution으로 초기화
- momentum없이 SGD 사용. learning rate는 0.7로 고정. 5 epoch 이후에는 0.5epoch마다 learning rate를 절반으로 줄임. 총 7.5 epoch 수행
- batch size는 128 사용
- LSTM을 사용하면 vanishing gradient 문제는 줄어들지만, exploding gradient 문제가 있음. 그래서 gradient norm에 hard constraint를 적용. gradient 값이 5보다 크면, 5로 고정한다.
- 각각의 sentence는 길이가 다르다. 대부분은 짧고, 일부는 길다. minibatch에는 짧은 문장이 많이 들어가고, 긴 문장은 일부만 들어간다. 길이가 다름에 따른 학습에 비효율이 존재한다. 그래서 비슷한 길이의 sentence가 minibatch에 들어가게 조정하였고, 학습 속도가 2배 빨라졌다.
Parallelization
하나의 GPU에서 초당 1,700개의 word를 처리할 수 있었는데, 이는 굉장히 느린 속도다. 그래서 8개의 GPU를 이용하여 병렬처리를 적용하였다. 각각의 layer는 서로 다른 GPU에서 처리되고, 처리가 완료되면 다음 GPU로 전달되어 처리된다. 나머지 4개의 GPU는 softmax를 병렬처리하는데 사용되었다. 이렇게 구현하여 초당 6,300개의 word를 처리할 수 있었고, 학습하는데 총 10일 가량이 소요되었다.
Experimental Results
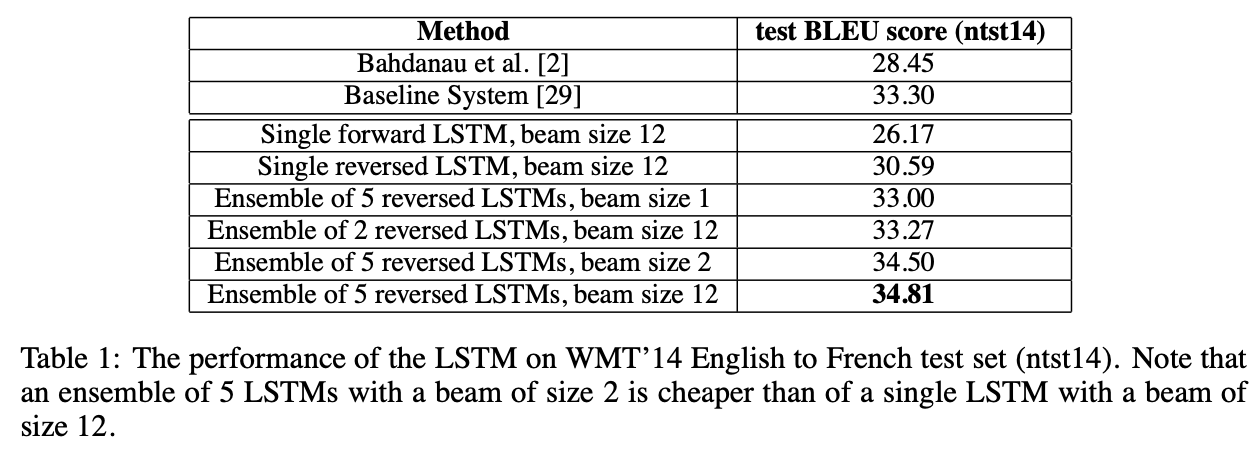

Performance on long sentences
LSTM이 긴 문장도 잘 처리하는 것을 볼 수 있다.
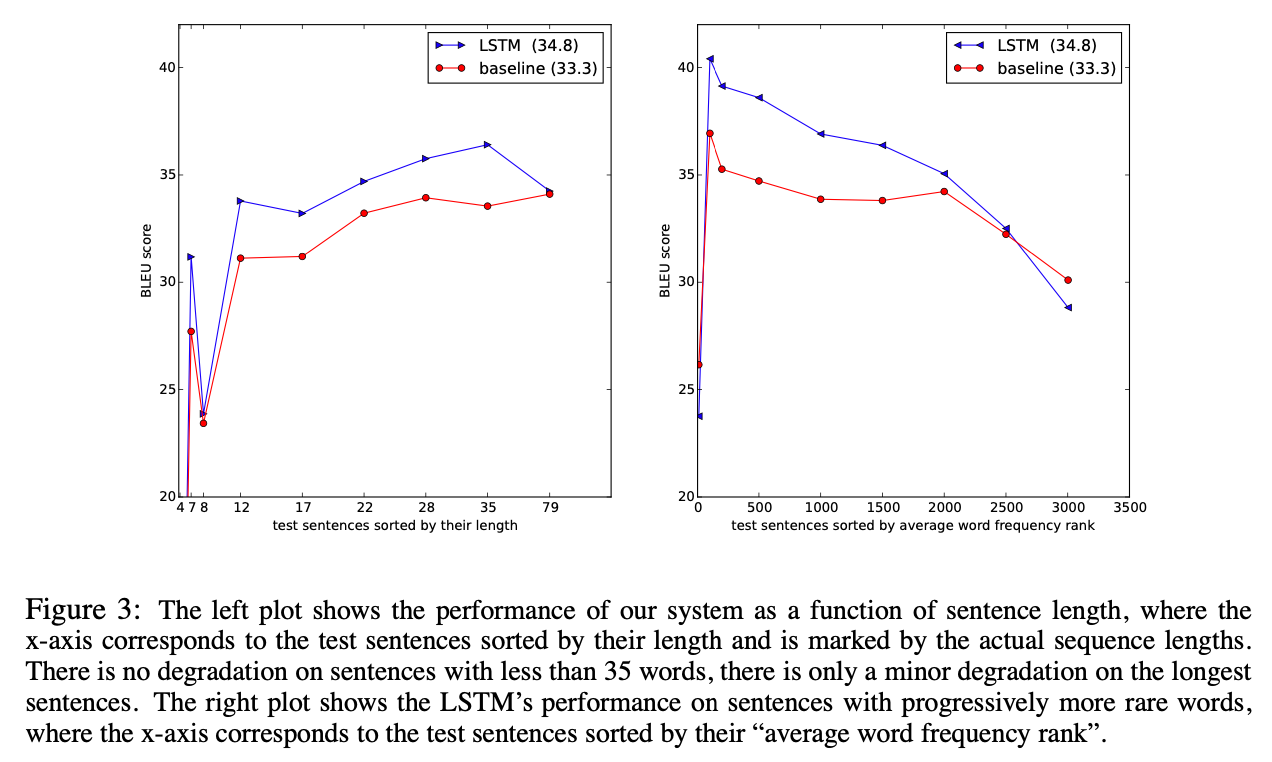
Model Analysis
본 모델의 장점 중 하나는 sequence word를 고정된 차원의 vector로 표현할 수 있다는 것이다.
학습된 표현을 visualize하면 아래와 같다.
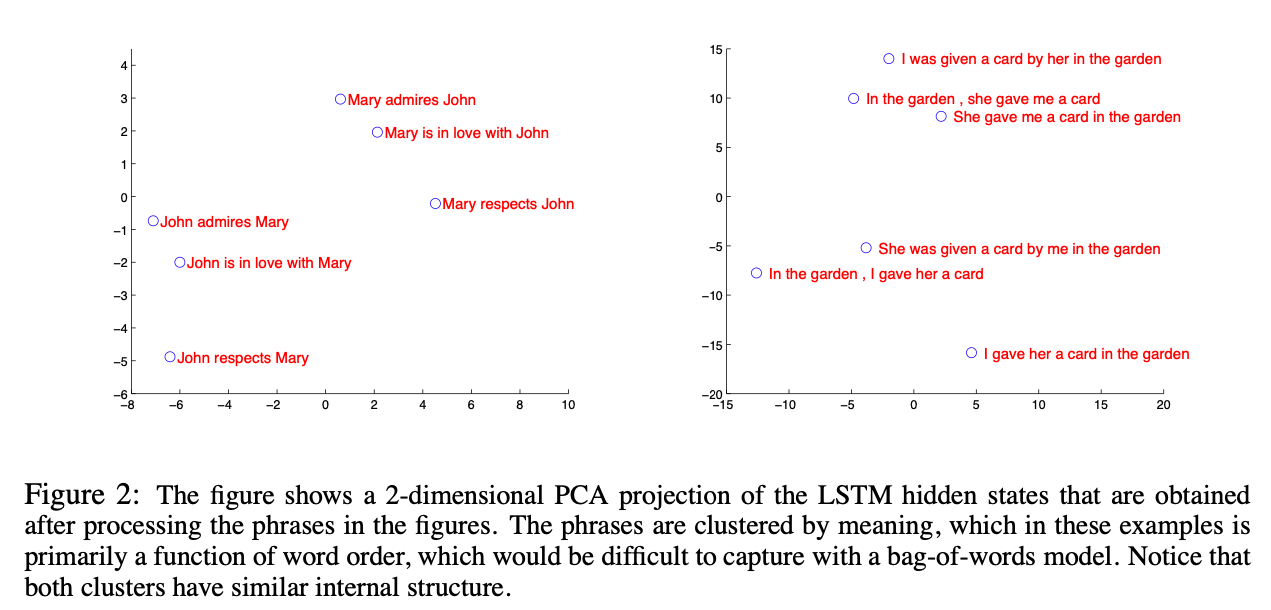
단어의 순서에는 민감하고, 능동태를 수동태로 대체하는데는 둔감한 것을 볼 수 있다.