[논문리뷰] SpanBERT: Improving Pre-training by Representing and Predicting Spans
Contents
Abstract
text의 span을 잘 표현하고 예측하는 pre-training 방법인 SpanBERT를 제안
- random token이 아닌 contiguous random span을 masking
- 개별 token representations에 의존하지 않고, masked span의 전체를 예측하기 위해 span boundary representations를 학습
Introduction
BERT와 같은 pre-training 방법은 개별 word나 subword 단위에서 강력한 성능을 보였다. 하지만 2개 이상의 span(범위) 간의 관계를 추론하는 question answering, coreference resolution과 같은 NLP task들이 존재한다.
span-level pre-training 방법인 SpanBERT는 BERT와 비교하여 2가지의 차이점이 존재한다.
첫째, 개별 token을 masking하지 않고 연속적인 spans를 masking한다.
둘째, span boundary objective를 사용하여 boundary token을 이용해 masking된 전체 span을 예측한다. boundary token에 span-level 정보가 저장되어 있어 fine-tuning시에도 쉽게 접근할 수 있다.
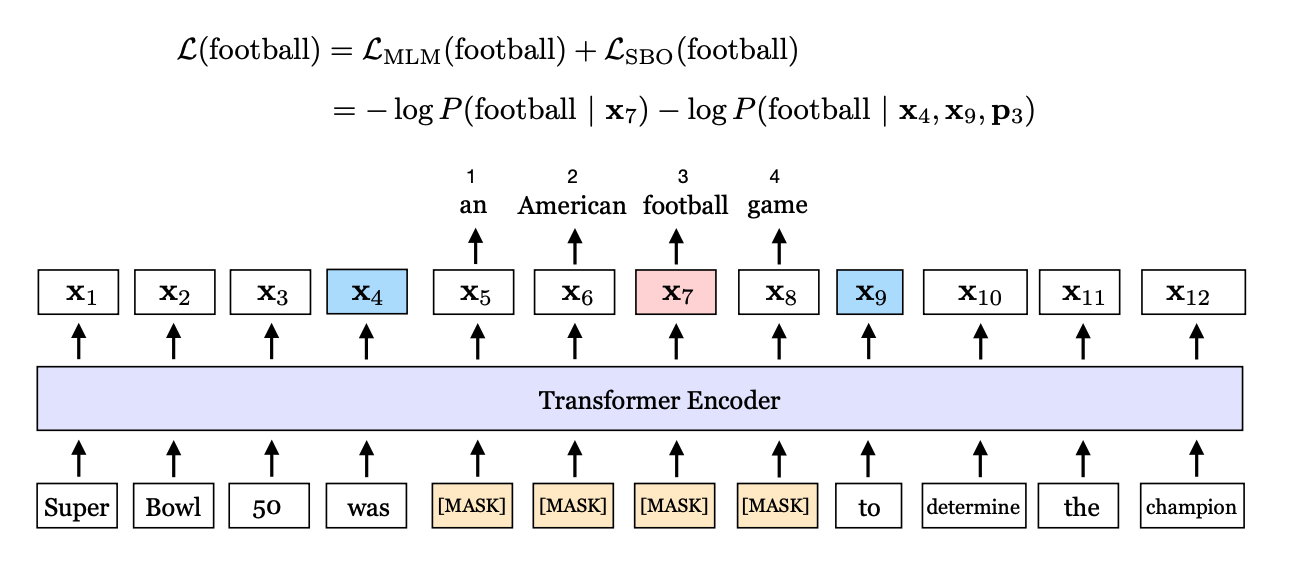
“an American football game"이 mask가 되어 있을 때, SBO는 x4와 x9를 boundary token으로 사용한다. p3는 fooball의 position embedding이다.
추가적으로 NSP를 제거하고, single segment를 사용하였다.
결과적으로 BERT와 비교하여 다양한 downstream task에서 BERT를 능가하는 성능을 보였다.
학습 데이터를 많이 사용하거나 모델 크기를 키우지 않고, 좋은 pre-training task와 objective만으로도 좋은 성능을 낼 수 있다는 것을 보여준다.
Model
Span Masking
전체 token에서 15%를 masking한다. 먼저 geometric distribution($\ell$ ~ Geo(p))을 이용하여 span의 길이를 정한다. 그 후 랜덤하게 시작점을 선택한다. 항상 subword가 아닌 전체 word를 선택한다. p는 0.2, $\ell_{max}$는 10을 사용하여 평균 span length $mean(\ell)$은 3.8이었다.
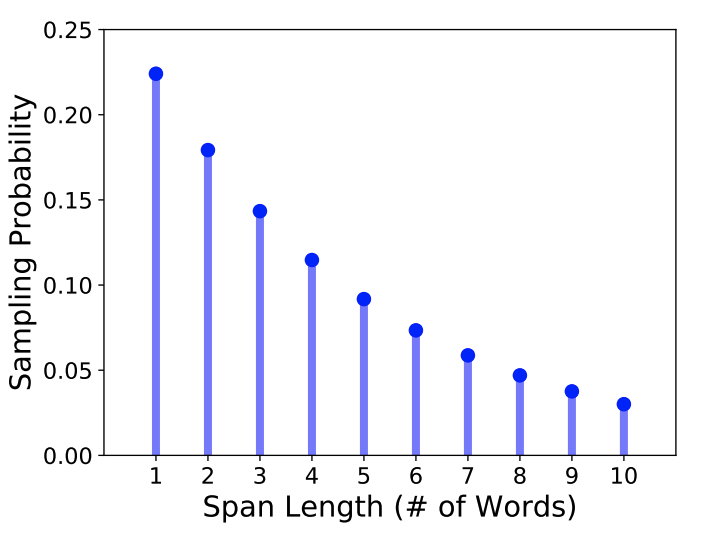
BERT와 동일하게 80%는 masking을 하고 10%는 random token을, 나머지 10%는 원본 token을 사용하였다.
Span Boundary Objective (SBO)
SpanBERT는 masked span의 양 끝에 있는 token들을 이용하여 각 masked token을 예측하는 span boundary objective를 사용하였다.
masked span이 $x_s, …, x_e$로 주어졌을때, 각 토큰 $x_i$는 positional embedding과 boundary token을 이용하여 표현된다. s와 e는 start, end position을 뜻하며, $x_{s-1}$과 $x_{e-1}$은 boundary token이다. $p_{i-s+1}$는 target token이며 boundary token 기준으로 상대적인 위치로 표시한다.
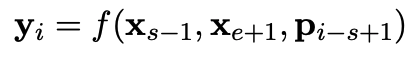
f(·)는 2 layer의 feed-forword network이며 GeLU activeation과 layer normalization을 사용한다.

vector ${y}_i$를 이용하여 token $x_i$를 예측하고 MLM objective와 같은 cross-entropy loss를 이용하여 계산한다.
최종적으로는 span boundary loss와 MLM loss를 합쳐서 사용한다.
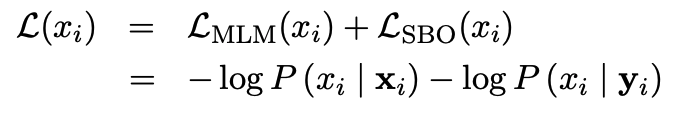
Single-Sequence Training
BERT에서 사용한 NSP를 제거하고, 하나의 sequence를 입력으로 사용하였다. single sequence가 NSP를 사용한 bi-sequence보다 좋은 이유는, 길이가 긴 full length를 사용할 수 있다는 점과 서로 다른 document에서 추출된 문장 2개는 MLM에서 noise를 만들어내기 때문이다. 그래서 최대 512 token을 가지는 하나의 연속적인 segment를 입력으로 사용하였다.
Implementation
기본적으로 BERT large의 설정을 가져와 사용하였고, 동일한 dataset을 사용하였다.
original BERT와 다른 점은 2가지 이다.
- epoch마다 masking을 다르게 적용
- short sequence를 샘플링하는 것을 제거하고 항상 512 token을 가지도록 만듬
Results
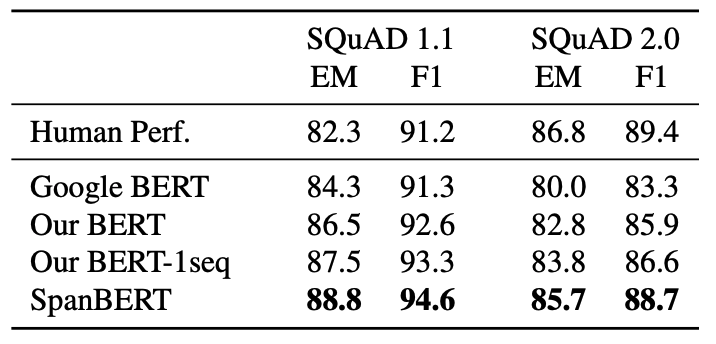
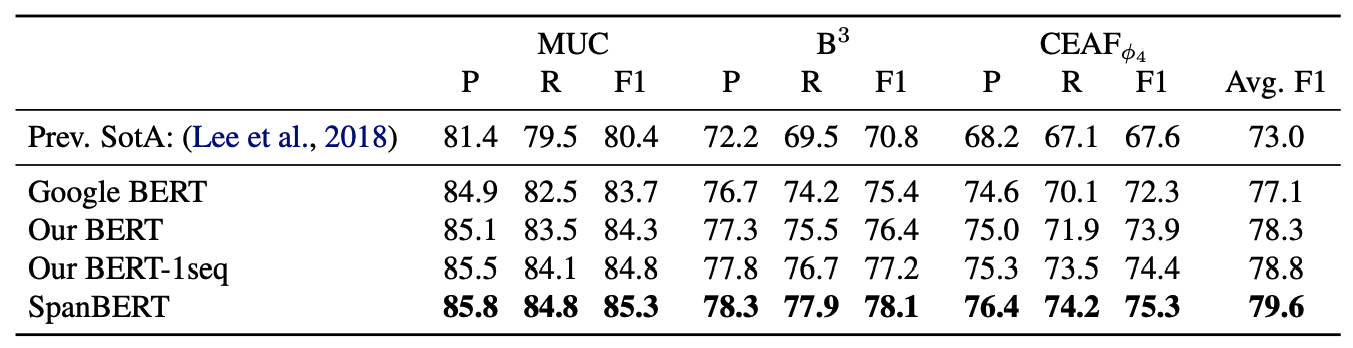
대부분의 task에서 SpanBERT가 BERT를 능가하였다. 또한 single sequence training이 NSP를 사용한 것보다 더 좋은 성능을 거둔 것을 확인할 수 있다.


Ablation Studies
Masking Schemes
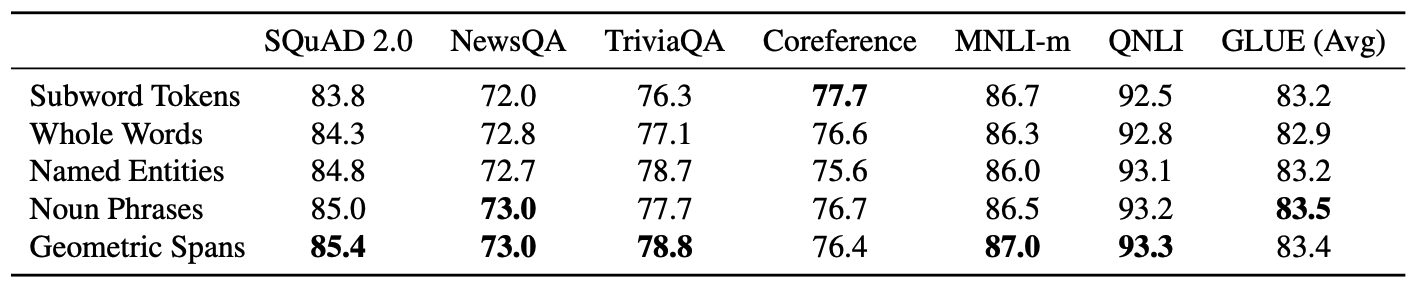
random span과 linguistically-informed span을 비교하였다.
linguistically-informed span(named entities, noun phrases)가 random span 대비 경쟁력 있는 성능을 보인 task가 있긴 하지만, 일관적으로 더 좋은 성능을 내지는 못했다.
Auxiliary Objectives
그 결과 single-sequence trainging을 하였을 때 성능이 더 좋아졌다. 또한 NSP와 달리 SBO를 추가였을 때 어떠한 나쁜 영향도 없었다.
